Strukturierte Daten für AI Search: Was JSON-LD leistet, wo es wirkt und was AI-Chatbots davon wirklich sehen
Schema.org-Markup ist unverzichtbar für Rich Results und Googles Knowledge Graph. Für AI-Chatbots läuft der Einfluss über einen anderen Kanal. Wer das verwechselt, optimiert für ein Verhalten, das so nicht existiert.
tl;dr
Die Kernaussagen auf einen Blick.
60 Prozent aller Suchanfragen enden ohne Klick. Strukturierte Daten sind eine technische Grundlage für klassische Rich Results und verbessern damit indirekt deine Chancen, von KI-Systemen als Quelle ausgewählt zu werden. Nicht mehr, aber auch nicht weniger.
Kernfakten:
- Schema.org-Markup liefert Googlebot maschinenlesbare Fakten – deterministisch, direkt in den Knowledge Graph. Das ist belegter, messbarer Effekt.
- KI-Chatbots wie ChatGPT, Perplexity oder Gemini funktionieren anders als Googlebot: Beim Abruf einer URL filtern ihre Parser alle <script>-Tags aktiv heraus. JSON-LD wird verworfen, bevor der Text das Sprachmodell erreicht. Das LLM liest deinen sichtbaren Text, nicht dein Schema.
- Der Zusammenhang zwischen JSON-LD und KI-Zitierungen ist indirekt und zweistufig: Gutes Schema verbessert klassische Rankings → bessere Rankings erhöhen die Wahrscheinlichkeit, von KI-Systemen als Quelle ausgewählt zu werden → das LLM liest dann den sichtbaren Text der Seite.
- 5 sauber implementierte, zum Geschäftsmodell passende Schema-Typen bringen mehr als 50 oberflächliche Markups.
Handlungsempfehlung:
Strukturierte-Daten-Audit durchführen (Google Rich Results Test), die wichtigsten Schema-Typen korrekt implementieren und dabei sicherstellen, dass alle im JSON-LD enthaltenen Informationen auch im sichtbaren Seitentext stehen. Was das LLM nicht lesen kann, nützt ihm nicht.
→ Im Hauptartikel: 15+ Schema-Typen mit Code-Beispielen, Implementierungs-Checkliste, Testverfahren und budgetspezifische Strategien
Mit dem Start von Google AI Overviews in Deutschland im März 2025, dem Aufstieg von KI-Suchmaschinen wie ChatGPT Search und Perplexity sowie der zunehmenden Integration künstlicher Intelligenz in alle großen Suchplattformen stehen Unternehmen vor einer zentralen Herausforderung: Wie machen sie ihre Inhalte für KI-Systeme verständlich und auffindbar?
Strukturierte Daten spielen dabei eine Rolle, aber eine andere als häufig behauptet wird. Googlebot liest JSON-LD deterministisch wie einen Datenbankimport. Sprachmodelle tun das nicht. Wer das verwechselt, optimiert für ein Verhalten, das in dieser Form nicht existiert. Dieser Leitfaden erklärt, was tatsächlich wirkt, was nur indirekt wirkt und wo die Branche gerade kollektiv einem Irrtum aufsitzt.
Die neue Realität der Suche: Von "10 blauen Links" zu KI-generierten Antworten
Die Suchmaschinen-Landschaft erlebt den größten Umbruch seit ihrer Entstehung. Was 1998 mit Googles PageRank-Algorithmus begann, hat sich fundamental gewandelt.
Moderne KI-Suchsysteme indexieren nicht mehr nur Dokumente, sie synthetisieren Wissen. Dieser Shift von Information Retrieval zu Answer Generation verändert die Spielregeln für digitale Sichtbarkeit grundlegend.
Die Zeitlinie dieser Transformation zeigt die Beschleunigung: Featured Snippets (2014), Voice Search-Integration (2016), BERT für semantisches Verstehen (2019), MUM für multimodale Suche (2021), und schließlich der Durchbruch generativer KI mit ChatGPT (November 2022), gefolgt von Google Bard/Gemini (2023) und dem globalen Rollout von AI Overviews (2024/2025). Was früher Jahre dauerte, geschieht heute in Monaten.
Für Website-Betreiber bedeutet das: Die klassische SEO-Strategie "Ranke auf Platz 1 und du gewinnst" ist allein nicht mehr ausreichend. Die neue Maxime lautet: Sei autoritativ, gut strukturiert und inhaltlich präzise, oder du wirst zunehmend unsichtbar. Strukturierte Daten sind ein wichtiger Teil davon, aber mit klar definierten Grenzen, die weiter unten erklärt werden.
Zero-Click Searches: Die Herausforderung für Website-Betreiber
Aktuelle Daten zeigen: Etwa 60 Prozent aller Suchanfragen enden ohne Klick auf ein Suchergebnis. Google AI Overviews, Featured Snippets und Knowledge Panels beantworten Nutzeranfragen direkt auf der Suchergebnisseite. Das stellt Unternehmen vor eine fundamentale Frage: Wie generieren sie Traffic, wenn Nutzer die Suchergebnisseite nicht mehr verlassen?
Die Lösung besteht nicht darin, gegen diese Entwicklung anzukämpfen, sondern die eigenen Inhalte so aufzubereiten, dass sie von KI-Systemen als Quelle ausgewählt und zitiert werden. Strukturierte Daten sind eine technische Grundlage dafür, allerdings auf einem indirekten Weg, der weiter unten genau erläutert wird.
Nochmal, weil es wichtig ist: Du musst deine Inhalte so gestalten, dass sie sowohl als vertrauenswürdige Quelle für KI-Antworten dienen als auch einen klaren Mehrwert bieten, der Nutzer zum Klick, zur Conversion oder zur direkten Bindung (Newsletter, API, App) motiviert.
Das Ökosystem der KI-Suche im Jahr 2025/2026
Die KI-Suchlandschaft umfasst mittlerweile mehrere Akteure:
Google AI Overviews: Seit März 2025 in Deutschland verfügbar, nutzen diese KI-generierten Zusammenfassungen das Gemini-Modell. Sie erscheinen prominent über den organischen Suchergebnissen und synthetisieren Informationen aus mehreren Quellen. Die Auswahl der zitierten Quellen basiert auf der Qualität der Seite im klassischen Suchindex, dem E-E-A-T-Profil und der inhaltlichen Klarheit des Texts.
Google AI Mode (KI-Modus): Der nächste evolutionäre Schritt nach den AI Overviews. Seit Oktober 2025 in Deutschland ausgerollt, stellt der AI Mode einen fundamentalen Paradigmenwechsel dar: Statt klassischer "10 blauer Links" bietet er eine vollständig dialogbasierte, KI-gesteuerte Suchoberfläche.
Exkurs: Der Google AI Mode
Technische Basis: Der AI Mode nutzt Gemini 2.5 und ein "Query-Fan-Out-Verfahren", bei dem eine Suchanfrage in Dutzende oder Hunderte Teilfragen zerlegt wird. Diese werden parallel recherchiert und zu einer kohärenten Antwort synthetisiert. Das System ist multimodal und verarbeitet Text-, Sprach- und Bildeingaben.
Funktionsweise: Anders als AI Overviews, die über regulären Suchergebnissen erscheinen, ist der AI Mode ein eigenständiger Tab (erreichbar über google.com/ai). Nutzer können Folgefragen stellen und einen echten Dialog führen, ohne neue Suchen starten zu müssen. Die Antworten enthalten Quellenangaben, aber keine klassischen Link-Listen.
Implikationen für Website-Betreiber: Der AI Mode zeigt weniger direkte Links als die klassische Suche. Website-Betreiber berichten seit dem US-Rollout im Mai 2025 von Traffic-Rückgängen im zweistelligen Prozentbereich. Google kontert, dass Suchanfragen im AI Mode 2–3 mal länger und komplexer seien und es sich um neue Fragestellungen handle, die vorher so nicht gestellt wurden. Der Modus ist bisher optional. Langfristig könnte er jedoch die Standard-Suche werden.
Strukturierte Daten im AI Mode: Gutes Schema.org-Markup hilft dabei, im klassischen Google-Index gut positioniert zu sein, was wiederum die Wahrscheinlichkeit erhöht, als Quelle im Query-Fan-Out-Prozess ausgewählt zu werden. Was dann mit dem abgerufenen Inhalt passiert, liegt beim Sprachmodell, das ausschließlich den sichtbaren Text verarbeitet.
ChatGPT Search: OpenAI hat seine Suchfunktion kontinuierlich ausgebaut. Das System durchsucht aktiv das Web und bevorzugt Inhalte, die klar strukturiert und inhaltlich präzise sind.
Perplexity: Diese spezialisierte KI-Suchmaschine hat sich auf research-intensive Anfragen fokussiert und zitiert ihre Quellen transparent. Websites mit qualitativ hochwertigen Inhalten haben deutlich höhere Chancen, als Quelle aufgeführt zu werden.
Microsoft Copilot: Die Integration in Bing und das Microsoft-Ökosystem macht Copilot zu einem relevanten Kanal, besonders im B2B-Bereich. Die Implementierung des Model Context Protocol (MCP) im Mai 2025 unterstreicht die strategische Bedeutung standardisierter Datenstrukturen.
Wie KI-Suchmaschinen funktionieren: Der Retrieval-Prozess
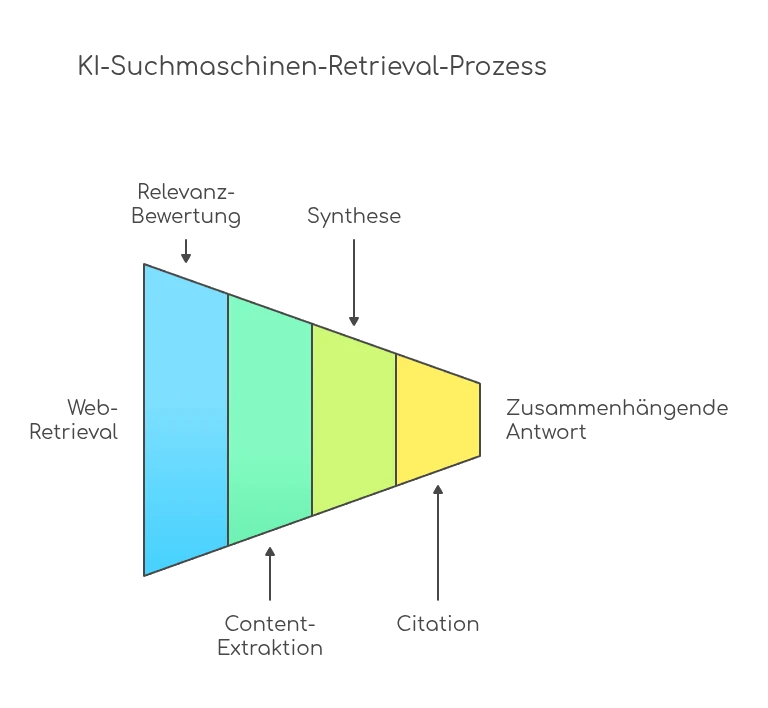
KI-Suchmaschinen folgen einem mehrstufigen Prozess. Das Verständnis dieser Stufen ist wichtig, um zu verstehen, wo strukturierte Daten wirken und wo nicht:
Web-Retrieval: Eine aktuelle Websuche wird durchgeführt (ChatGPT über Bing, Google über den eigenen Index, Perplexity über mehrere Quellen)
Relevanz-Bewertung: Das System bewertet die Relevanz der Treffer anhand von Suchindex-Signalen. Strukturierte Daten können hier indirekt helfen, weil sie klassische Rankings verbessern.
Content-Extraktion: Von ausgewählten Seiten ruft der KI-Crawler den Seiteninhalt ab. HTML-to-Text-Parser wie Trafilatura oder Mozilla Readability.js konvertieren das rohe HTML in sauberes Markdown. Dabei werden alle
<script>-Tags aktiv herausgefiltert. Das bedeutet: JSON-LD wird in diesem Schritt vollständig verworfen, bevor der Text das Sprachmodell erreicht.Synthese: Das Sprachmodell erstellt aus dem extrahierten sichtbaren Text eine zusammenhängende Antwort.
Zitation: Die wichtigsten Quellen werden mit Links versehen.
Ein empirisches Experiment von SearchVIU aus dem Jahr 2025, das fünf KI-Systeme (Google AI Overviews, Perplexity, ChatGPT, Claude und Gemini) testete, bestätigte: Keines der Systeme extrahierte Informationen, die ausschließlich im JSON-LD hinterlegt waren.
Ergänzend dazu hält die akademische Studie arXiv:2603.10700 (März 2026) fest, dass aktuelle RAG-Systeme strukturierte Metadaten wie JSON-LD nicht nativ verarbeiten, obwohl Websites sie zunehmend einbetten.
Websites, die keine strukturierten Daten bereitstellen, haben es schwerer, im klassischen Suchindex gut positioniert zu sein und damit indirekt schwerer, als Quelle für KI-Systeme ausgewählt zu werden. Der Weg ist länger als oft behauptet, aber er existiert.
Was sind strukturierte Daten und warum sind sie wichtig?
Das World Wide Web wurde ursprünglich für Menschen konzipiert: HTML strukturiert Inhalte visuell, CSS gestaltet sie ästhetisch, und JavaScript macht sie interaktiv. Mit dem Aufstieg intelligenter Systeme entstand eine neue Anforderung: Maschinen müssen nicht nur rendern, sondern verstehen.
Für Googles Suchmaschine ist strukturiertes Markup bis heute unverzichtbar. Strukturierte Daten lösen ein fundamentales Problem: Sie übersetzen implizites Wissen in explizite Fakten. Was für Menschen offensichtlich ist ("Dieser Text beschreibt ein Produkt mit Preis"), muss für Suchmaschinen kodifiziert werden. Diese Kodifizierung ist keine technische Spielerei, sie entscheidet darüber, ob eine Seite Rich Results bekommt und wie sie im Knowledge Graph eingeordnet wird.
Für AI-Chatbots läuft das über einen anderen Kanal: Sie wählen Quellen auf Basis klassischer Suchindex-Signale aus, verarbeiten dann aber nur den sichtbaren Text. Das macht eine inhaltlich klare, gut strukturierte Seite mit sauberem sichtbarem Text zum entscheidenden Faktor auf der Syntheseebene.
Der fundamentale Unterschied zwischen Googlebot und Sprachmodellen
Menschen können aus natürlicher Sprache Kontext und Bedeutung ableiten. Ein Mensch erkennt sofort, dass "Dr. Maria Schmidt, Kardiologin am Universitätsklinikum München" eine Ärztin mit Spezialisierung und Arbeitsort beschreibt.
Googlebot arbeitet deterministisch: Er liest JSON-LD nach festen Regeln wie einen Datenbankimport. Die Daten fließen direkt in Googles Knowledge Graph ein. Das ermöglicht Rich Results: Sternebewertungen, Preise, FAQs, Veranstaltungsdaten direkt in der Trefferliste. Das ist dokumentiertes, messbares Verhalten.
{
"@context": "https://schema.org",
"@type": "Person",
"name": "Dr. Maria Schmidt",
"jobTitle": "Kardiologin",
"worksFor": {
"@type": "Hospital",
"name": "Universitätsklinikum München"
}
}Googlebot legt diese Daten ab. Er "liest" sie nicht im semantischen Sinne, er indexiert sie.
Sprachmodelle funktionieren grundlegend anders: Sie sind probabilistische Textgeneratoren, optimiert für semantisches Verständnis aus sichtbarem Text. Wenn ein KI-Crawler eine Seite abruft, übergibt er dem Sprachmodell nicht das rohe HTML, sondern sauberes Markdown. Komplexe JSON-Syntax verschwendet dabei wertvolle Tokens im Kontextfenster, ohne semantischen Mehrwert zu liefern. Der Grund für das aktive Herausfiltern von <script>-Tags ist technisch und ökonomisch: Token-Effizienz geht vor.
Falls ein LLM doch versehentlich tief verschachteltes JSON-LD aufnimmt, liest es es als flache Sequenz von Text-Tokens. Die hierarchischen Beziehungen der JSON-Arrays gehen dabei verloren.
Was das für die Praxis bedeutet
Die Verwechslung entsteht, weil der Prozess zweistufig ist und Marketers nur das Ergebnis sehen: Die Seite hat JSON-LD. Die KI zitiert die Seite. Also hat JSON-LD geholfen. In Wirklichkeit hat JSON-LD die Sichtbarkeit im klassischen Suchindex verbessert, was dazu geführt hat, dass das KI-System die Seite als Quelle ausgewählt hat. Der sichtbare Text hat dann die Antwort geliefert, nicht das Schema.
Daraus folgt ein praktisches Prinzip, das der Grounding-Page-Ansatz (Hanns Kronenberg) konsequent umsetzt: Alles, was im JSON-LD steht, muss auch im sichtbaren HTML stehen. Nicht als optionaler Zusatz, sondern als Pflicht. Denn was das LLM nicht im sichtbaren Text findet, findet es nirgends.
Strukturierte Daten als indirekter Ranking-Faktor
Eine häufig gestellte Frage: Sind strukturierte Daten ein direkter Ranking-Faktor bei Google? Die Antwort ist differenziert.
Aktuelle Studien, darunter die Semrush Ranking Factors Study 2024, zeigen:
Die bloße Verwendung von Schema.org-Markup korreliert nur schwach mit besseren Rankings
Spezifische Auszeichnungen wie Sternebewertungen zeigen eine stärkere Korrelation mit Top-Positionen
Strukturierte Daten wirken primär indirekt über erhöhte Click-Through-Rates durch Rich Snippets
Sie verbessern die Chance, in AI Overviews, Knowledge Panels und Featured Snippets zu erscheinen
Die strategische Implikation: Fokus auf qualitativ hochwertige Implementierung relevanter Schema-Typen statt auf Masse. Fünf perfekt implementierte, zum Geschäftsmodell passende Schema-Auszeichnungen bringen mehr als 50 oberflächlich implementierte Markups.
Schema.org als Standard für maschinenlesbare Datenstrukturen
In der Technologiegeschichte gibt es Momente, in denen Wettbewerber erkennen, dass Kooperation allen mehr nutzt als Konkurrenz. Schema.org entstand 2011 aus genau solch einer Situation: Google, Microsoft (Bing), Yahoo und Yandex einigten sich auf ein gemeinsames Vokabular für strukturierte Daten.
Heute nutzen über 45 Millionen Websites Schema.org-Markup. Diese kritische Masse erzeugt einen selbstverstärkenden Effekt: Je mehr Websites Schema.org verwenden, desto besser können Suchmaschinen damit arbeiten. Je besser die Systeme damit arbeiten, desto größer der Anreiz für weitere Websites, es zu implementieren.
Für KMU und Mittelstand bedeutet das: Die Frage ist nicht mehr "Soll ich strukturierte Daten verwenden?", sondern "Welche Schema-Typen sind für mein Geschäftsmodell relevant?"
Geschichte und Entwicklung
Schema.org entstand 2011 als Kooperationsprojekt der vier großen Suchmaschinen. Seit der Gründung hat sich das Vokabular kontinuierlich weiterentwickelt und umfasst heute über 800 Typen und mehr als 1.450 Eigenschaften. Die Entwicklung erfolgt transparent über einen Community-Prozess der W3C Schema.org Community Group.
Hinweis zu Deprecations: Im November 2025 hat Google angekündigt, ab Januar 2026 den Support für sieben strukturierte Daten-Typen einzustellen, darunter Practice Problem, Dataset (für die allgemeine Suche), Sitelinks Search Box, SpecialAnnouncement und Q&A. Das ist keine Abkehr von strukturierten Daten, sondern eine Bereinigung wenig genutzter Typen. Ranking-Einbußen entstehen dadurch nicht, betroffene Seiten erhalten für diese Typen keine Rich Results mehr.
Branchenspezifische Schema-Typen: Was für dein Unternehmen relevant ist
Die Auswahl der richtigen Schema-Typen hängt von deiner Branche ab:
E-Commerce und Retail
Product: Grundlegende Produktinformationen (Name, Beschreibung, Bild, SKU)
Offer: Preis, Verfügbarkeit, Lieferbedingungen, Händlerinformationen
AggregateRating: Durchschnittsbewertung basierend auf Kundenrezensionen
Review: Einzelne Kundenbewertungen mit Bewertung, Text und Autor
Brand: Markeninformationen für Markenprodukte
Breadcrumbs: Navigationspfad für bessere Orientierung
Praxistipp für KMU: Eine mittelständische E-Commerce-Website sollte mindestens Product, Offer und AggregateRating implementieren. Die Investition in diese drei Schema-Typen zahlt sich durch verbesserte Rich Snippets und höhere CTR am schnellsten aus.
Lokale Unternehmen und Dienstleister
Article: Nachrichtenartikel und Blogbeiträge
NewsArticle: Spezielle Auszeichnung für nachrichtliche Inhalte
BlogPosting: Blog-spezifische Markierungen
Person: Autoreninformationen mit Qualifikationen und Expertise
VideoObject: Videoinhalte mit Metadaten
HowTo: Schritt-für-Schritt-Anleitungen
FAQPage: Häufig gestellte Fragen mit Antworten
Praxistipp für KMU: Article-Markup kombiniert mit vollständigen Person-Markups für Autoren stärkt E-E-A-T-Signale (Experience, Expertise, Authoritativeness, Trustworthiness) und erhöht die Chance auf Zitation in AI Overviews.
B2B und Professional Services
ProfessionalService: Professionelle Dienstleistungen (Beratung, Rechtsanwälte, Architekten)
JobPosting: Stellenausschreibungen
Course: Schulungs- und Weiterbildungsangebote
Event: Veranstaltungen, Webinare, Konferenzen
CreativeWork: Whitepapers, Studien, Fallstudien
Praxistipp für KMU: B2B-Unternehmen sollten ProfessionalService mit detaillierten Service-Beschreibungen und Event-Markups für Webinare kombinieren.
Die Bedeutung von Nested Structures
Schema.org-Markups entfalten ihre volle Kraft durch Verschachtelung. Ein Product-Schema sollte nicht isoliert stehen, sondern Offer, Brand, AggregateRating und weitere relevante Typen einbinden:
{
"@context": "https://schema.org",
"@type": "Product",
"name": "Professionelles CRM-System für KMU",
"description": "Cloud-basiertes CRM mit KI-gestützter Lead-Qualifizierung",
"brand": {
"@type": "Brand",
"name": "TechSolutions GmbH"
},
"offers": {
"@type": "Offer",
"price": "49.00",
"priceCurrency": "EUR",
"availability": "https://schema.org/InStock",
"priceValidUntil": "2025-12-31"
},
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.7",
"reviewCount": "143"
}
}Diese verschachtelten Strukturen liefern Googlebots Knowledge Graph ein umfassendes Bild und ermöglichen präzisere Rich Results.
JSON-LD: Das bevorzugte Implementierungsformat
Schema.org definiert WAS ausgezeichnet werden soll, nicht aber WIE die Auszeichnung technisch erfolgt. Für neu implementierte strukturierte Daten ist die Format-Frage faktisch beantwortet: JSON-LD dominiert mit geschätzten 70–80 Prozent Marktanteil.
Als Google 2016 JSON-LD offiziell als bevorzugtes Format empfahl, war das mehr als eine technische Präferenz. Content-Management-Systeme, SEO-Plugins und Entwickler-Tools orientierten sich daran.
Technische Vorteile von JSON-LD
Separation of Concerns: JSON-LD trennt die strukturierten Daten vollständig vom sichtbaren HTML-Code. Das erleichtert Wartung und reduziert das Risiko von Fehlern bei Design-Änderungen.
Einfachere Implementierung: Ein JavaScript-Block im <head>- oder <body>-Bereich genügt. Keine komplexe Verschachtelung mit HTML-Elementen.
Bessere Skalierbarkeit: Strukturierte Daten können zentral generiert und auf beliebig vielen Seiten eingefügt werden.
Reduzierte Fehleranfälligkeit: Da JSON-LD vom sichtbaren Content getrennt ist, können Änderungen am Layout die strukturierten Daten nicht versehentlich beschädigen.
Microdata und RDFa: Wann sie sinnvoll sind
Obwohl JSON-LD präferiert wird, gibt es Szenarien für Microdata oder RDFa: Legacy-Systeme, in denen eine Migration aufwändig wäre, oder sehr spezifische Nischen-Anforderungen. Wichtig: Keine Mischung verschiedener Formate für denselben Inhalt. Neues Schema-Markup sollte grundsätzlich in JSON-LD implementiert werden.
Praktisches Implementierungsbeispiel: Lokales Unternehmen
Ein vollständiges Beispiel für ein lokales Unternehmen:
{
"@context": "https://schema.org",
"@type": "LocalBusiness",
"@id": "https://beispiel-schreinerei.de/#organization",
"name": "Meisterschreinerei Schmidt GmbH",
"description": "Traditionelle Schreinerei mit modernster CNC-Technik. Individuelle Möbel und Innenausbau seit 1985.",
"url": "https://beispiel-schreinerei.de",
"telephone": "+49-89-12345678",
"email": "info@beispiel-schreinerei.de",
"logo": {
"@type": "ImageObject",
"url": "https://beispiel-schreinerei.de/logo.png",
"width": "600",
"height": "60"
},
"address": {
"@type": "PostalAddress",
"streetAddress": "Hauptstraße 123",
"addressLocality": "München",
"postalCode": "80331",
"addressCountry": "DE"
},
"geo": {
"@type": "GeoCoordinates",
"latitude": "48.1351",
"longitude": "11.5820"
},
"openingHoursSpecification": [
{
"@type": "OpeningHoursSpecification",
"dayOfWeek": ["Monday", "Tuesday", "Wednesday", "Thursday", "Friday"],
"opens": "08:00",
"closes": "17:00"
}
],
"priceRange": "€€-€€€",
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.8",
"reviewCount": "67"
},
"sameAs": [
"https://www.facebook.com/beispiel-schreinerei",
"https://www.instagram.com/beispiel-schreinerei"
]
}Dieses Markup liefert Googlebot alle relevanten Informationen für lokale Suchanfragen und Knowledge Panel-Einträge. Alle Informationen, die hier stehen, müssen auch im sichtbaren Seitentext vorhanden sein.
Rich Snippets und Rich Results: Sichtbarkeit in den Suchergebnissen
Die Google-Suchergebnisseite ist digitales Hochpreisimmobilien-Territorium. Ein Rich Snippet auf Platz 3 kann mehr Klicks generieren als ein Standard-Suchergebnis auf Platz 1. Das begann 2009 mit den ersten Rich Snippets und entwickelte sich zum strategischen Differenzierungsmerkmal.
Heute konkurrieren Featured Snippets, Knowledge Panels, Video-Karussells, Shopping-Ergebnisse, lokale Pack-Einträge, FAQ-Boxen und klassische organische Treffer um Aufmerksamkeit – und nur ein Bruchteil davon sind klassische "blaue Links".
Ein Standard-Snippet mit 156 Zeichen Meta Description nimmt etwa 3–4 Zentimeter Bildschirmfläche ein. Ein vollständiges Rich Snippet mit Sternebewertung, Preis, Verfügbarkeit und Produktbild kann 8–12 Zentimeter beanspruchen. Diese zusätzliche Fläche übersetzt sich direkt in höhere Click-Through-Rates und qualifizierten Traffic.
Was sind Rich Snippets und wie entstehen sie?
Rich Snippets (auch Rich Results genannt) sind angereicherte Suchergebnisse, die über den Standard-Dreizeiler hinausgehen. Sie enthalten zusätzliche visuelle Elemente: Sternebewertungen, Preisangaben, Verfügbarkeiten, Produktbilder, Rezeptzutaten und Kochzeiten, Event-Termine, Video-Thumbnails mit Dauer, Schritt-für-Schritt-Anleitungen.
Rich Snippets entstehen, wenn Google strukturierte Daten auf einer Webseite erkennt, validiert und für die Darstellung aufbereitet.
Wichtige Einschränkung: Die Implementierung strukturierter Daten garantiert keine Rich Snippets. Google entscheidet algorithmisch, wann und für welche Suchanfragen Rich Snippets ausgespielt werden. Faktoren sind die Qualität und Vollständigkeit der strukturierten Daten, die Relevanz für die Suchanfrage, die Vertrauenswürdigkeit der Domain, der Wettbewerb in den Suchergebnissen und Nutzersignale.
Die wichtigsten Rich Snippet-Typen für KMU
Produkt Rich Snippets
Darstellung: Produktbild, Preis, Verfügbarkeit, Sternebewertung.
Voraussetzung: Product-, Offer- und AggregateRating-Schema.
Mehrwert: Deutlich erhöhte CTR, besonders bei transaktionalen Suchanfragen.
FAQ Rich Snippets
Darstellung: Aufklappbare Frage-Antwort-Paare direkt in den Suchergebnissen. Voraussetzung: FAQPage-Schema mit mindestens zwei Frage-Antwort-Paaren.
Wichtiger Hinweis (Stand 2025/2026): Seit August 2023 zeigt Google FAQ Rich Snippets nur noch für bekannte, autoritative Regierungs- und Gesundheitswebsites an. Für die meisten anderen Websites werden FAQ Rich Snippets nicht mehr in den klassischen Suchergebnissen ausgespielt. FAQ-Schemas sollten aber trotzdem implementiert bleiben, weil sie Googles semantisches Verständnis der Inhalte unterstützen und das FAQPage-Schema weiterhin nicht zu den im Januar 2026 deprecateten Typen gehört.
HowTo Rich Snippets
Darstellung: Schritt-für-Schritt-Anleitung mit Bildern, Gesamtdauer, benötigten Materialien.
Voraussetzung: HowTo-Schema mit strukturierten Steps.
Einsatzgebiete: Anleitungen, Tutorials, DIY-Projekte, Reparaturanleitungen.
Event Rich Snippets
Darstellung: Datum, Uhrzeit, Veranstaltungsort, Ticket-Verfügbarkeit.
Relevanz für B2B: Webinare, Messen, Netzwerk-Events, Schulungen.
Die Beziehung zwischen Rich Snippets und AI Overviews
Ein häufig falsch beschriebener Zusammenhang: Strukturierte Daten erhöhen die Chance auf Rich Snippets. Rich Snippets und gute klassische Rankings erhöhen die Vertrauenswürdigkeit und Indexierungsqualität einer Domain. Das wiederum erhöht die Wahrscheinlichkeit, dass ein KI-System die Seite als Quelle auswählt. Es ist eine indirekte Kette, keine direkte Verbindung. Das LLM liest dann den sichtbaren Text, nicht das Schema.
Wer in AI Overviews zitiert wird, profitiert von einem Autoritätssignal, das wiederum die Chance auf Rich Snippets und bessere Rankings verstärkt. Dieser selbstverstärkende Effekt entsteht, weil Autorität und Inhaltsqualität die gemeinsame Grundlage bilden.
Der Knowledge Graph: Wie Unternehmen zur Entität werden
Im September 2013 vollzog Google mit dem Hummingbird-Update den Übergang von der "String-based Search" zur "Entity-based Search". Statt Webseiten nach Übereinstimmung von Zeichenketten zu durchsuchen, begann Google, Konzepte, Personen, Orte und Organisationen als eigenständige Entitäten mit Eigenschaften und Beziehungen zu verstehen. Dieses semantische Netzwerk ist Googles Knowledge Graph.
Die sichtbarste Manifestation sind Knowledge Panels. Ein Knowledge Panel signalisiert: Google hat dich als Entität erkannt, validiert und in sein semantisches Wissensnetz integriert.
Für KMU und Mittelstand ist der Weg ins Knowledge Panel traditionell schwierig gewesen. Strukturierte Daten haben diese Dynamik verändert: Sie ermöglichen es auch kleineren Unternehmen, sich als Entität zu etablieren.
Was ist der Google Knowledge Graph?
Der Knowledge Graph ist Googles semantische Wissensdatenbank, die Milliarden von Entitäten (Personen, Orte, Unternehmen, Produkte, Konzepte) und ihre Beziehungen zueinander speichert. Er bildet die Grundlage für Knowledge Panels, Featured Snippets und Antwortboxen, Google Assistant-Antworten und AI Overviews.
Der Weg ins Knowledge Panel: Strategien für KMU
Schritt 1: Entitätsetablierung durch strukturierte Daten
Implementiere ein vollständiges Organization-Schema auf der Hauptseite:
{
"@context": "https://schema.org",
"@type": "Organization",
"@id": "https://ihrunternehmen.de/#organization",
"name": "Ihr Unternehmensname",
"alternateName": "Bekannte Abkürzung",
"url": "https://ihrunternehmen.de",
"logo": {
"@type": "ImageObject",
"url": "https://ihrunternehmen.de/logo-1200x1200.png",
"width": "1200",
"height": "1200"
},
"description": "Detaillierte Unternehmensbeschreibung (mind. 100 Zeichen)",
"foundingDate": "1995-06-15",
"address": {
"@type": "PostalAddress",
"streetAddress": "Musterstraße 123",
"addressLocality": "Musterstadt",
"postalCode": "12345",
"addressCountry": "DE"
},
"sameAs": [
"https://www.linkedin.com/company/ihrunternehmen",
"https://www.xing.com/company/ihrunternehmen",
"https://de.wikipedia.org/wiki/Ihr_Unternehmen"
]
}Schritt 2: Wikidata-Eintrag erstellen
Wikidata ist eine zentrale Datenquelle für den Knowledge Graph. Die Erstellung ist kostenlos, erfordert aber die Einhaltung von Relevanzkriterien (Medienberichterstattung in unabhängigen Quellen, mehrjährige Unternehmenshistorie). Für KMU ohne Wikipedia-Präsenz ist Wikidata oft der pragmatischere Weg.
Schritt 3: Konsistente NAP-Daten (Name, Address, Phone)
Absolute Konsistenz in den Unternehmensdaten über alle Plattformen: offizielle Website, Google Business Profile, Branchenverzeichnisse, Social Media Profile, Pressemitteilungen. Inkonsistenzen verzögern oder verhindern die Knowledge Graph-Integration.
Schritt 4: Google Business Profile optimieren
Ein vollständig ausgefülltes, regelmäßig gepflegtes Google Business Profile ist für lokale Unternehmen oft der direkteste Weg ins Knowledge Panel.
Schritt 5: Autorität und Verlinkungen aufbauen
Der Knowledge Graph bevorzugt Entitäten mit etablierter Autorität: Erwähnungen in relevanten Medien, Branchenawards, Zertifizierungen, Partnerschaften mit bekannten Marken.
Knowledge Graph für Personen: Personal Branding
Für Geschäftsführer, Fachexperten und Thought Leader ist ein persönliches Knowledge Panel wertvoll:
{
"@context": "https://schema.org",
"@type": "Person",
"@id": "https://ihrewebsite.de/#person",
"name": "Dr. Maria Schmidt",
"jobTitle": "Geschäftsführerin",
"worksFor": {
"@type": "Organization",
"name": "TechSolutions GmbH"
},
"url": "https://ihrewebsite.de",
"description": "Expertin für digitale Transformation im Mittelstand mit 15 Jahren Erfahrung in der IT-Beratung",
"sameAs": [
"https://www.linkedin.com/in/maria-schmidt",
"https://www.xing.com/profile/Maria_Schmidt"
],
"knowsAbout": ["Digitale Transformation", "Change Management", "IT-Strategie"]
}Kombiniere das Person-Schema mit den Autoren-Markups auf Blog-Artikeln und Fachbeiträgen. Das stärkt die Expertise-Signale.
KI-gestützte Suchsysteme: Optimierung für das neue Paradigma
Large Language Models funktionieren fundamental anders als klassische Suchmaschinen-Crawler. Sie ranken nicht, sie synthetisieren. Sie crawlen nicht sequenziell, sie verstehen kontextuell. Während klassisches SEO fragte "Wie ranke ich auf Platz 1?", fragt AI-Search Optimization: "Wie werde ich als Quelle zitiert?" Während SEO auf Sichtbarkeit in Rankings abzielte, zielt AI-Search Optimization auf Zitierwürdigkeit in generierten Antworten.
Für Marketing-Verantwortliche bedeutet das: Die SEO-Playbooks der letzten 20 Jahre sind nicht wertlos, aber unvollständig. Strukturierte Daten bilden die Grundlage für gute klassische Rankings. Gute klassische Rankings sind die Grundlage dafür, als Quelle für KI-Systeme ausgewählt zu werden. Was dann auf der Syntheseebene zählt, ist der sichtbare Text.
AI-Search Optimization als neue Disziplin
AI-Search Optimization (in der Branche auch als GEO, AEO oder GAIO bezeichnet) fokussiert auf die Optimierung von Inhalten für KI-generierte Antworten in Systemen wie Google AI Overviews, ChatGPT, Perplexity und Microsoft Copilot.
Die fünf zentralen Faktoren für AI-Search Optimization:
1. Zitierfähigkeit (Citability)
KI-Systeme suchen Content, der als "Antwortbaustein" funktioniert. Charakteristika zitierfähiger Inhalte: klare, präzise Aussagen ohne Umschweife, Fakten mit konkreten Zahlen und Studienreferenzen, definitorische Sätze ("X ist...", "X bezeichnet..."), Vergleiche und Auflistungen, Prozessbeschreibungen mit eindeutigen Schritten.
2. Sichtbarer Textinhalt mit klarer semantischer Struktur
Das ist der entscheidende Punkt für die Syntheseebene: Sprachmodelle lesen den sichtbaren Text. Was das LLM verarbeitet, ist das Markdown, das aus dem HTML-Parsing entsteht. Daraus folgen konkrete Anforderungen:
Klare HTML-Struktur (H1, H2, H3 in logischer Hierarchie) - diese Hierarchie überlebt den Parser und gibt dem LLM Orientierung
Semantische HTML5-Elemente (article, section, aside, nav) – bleiben im geparsten Text erhalten
Alt-Texte für Bilder mit kontextuellen BeschreibungenStrukturierte Listen (ol, ul) statt Fließtext-Aufzählungen – Markdown-Listen sind für LLMs effizienter verarbeitbar
JSON-LD: Unverzichtbar für Googlebots Knowledge Graph und Rich Results, aber kein direkter Hebel für das Sprachmodell. Der Umweg über den Suchindex ist real und wichtig.
3. Autorität und E-E-A-T
KI-Systeme bewerten Quellenglaubwürdigkeit. Signale für Autorität: detaillierte Autorenprofile mit Qualifikationen, externe Verlinkungen zu autoritativen Quellen, Zitationen durch andere Websites, konsistente Fachexpertise über mehrere Artikel.
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Dein Artikeltitel",
"author": {
"@type": "Person",
"name": "Dr. Max Experte",
"jobTitle": "Senior Consultant Digital Marketing",
"affiliation": {
"@type": "Organization",
"name": "Deine Firma"
},
"url": "https://deinewebsite.de/autoren/max-experte",
"sameAs": "https://www.linkedin.com/in/maxexperte"
},
"publisher": {
"@type": "Organization",
"name": "Deine Firma",
"logo": {
"@type": "ImageObject",
"url": "https://deinewebsite.de/logo.png"
}
},
"datePublished": "2025-10-15",
"dateModified": "2025-10-20"
}4. Kontextuelle Tiefe und semantische Abdeckung
KI-Systeme bevorzugen Inhalte mit umfassender Themenabdeckung. Tiefgehende Analysen (1.500–3.000 Wörter für komplexe Themen), Berücksichtigung verwandter Themen und Fragen, Themenclustering (mehrere inhaltlich verknüpfte Artikel), interne Verlinkung zwischen thematisch verwandten Inhalten.
5. Technische Zugänglichkeit
Keine Blockierung von KI-Crawlern in robots.txt (GPTBot, ClaudeBot, OAI-SearchBot), schnelle Ladezeiten, Mobile-First-Design, Strukturierte Daten ohne Fehler, klare XML-Sitemap, keine Paywalls für fundamentalen Content.
Kritischer Fehler: Viele Websites blockieren versehentlich KI-Crawler. Prüfe deine robots.txt auf Einträge wie:
User-agent: GPTBot
Disallow: /Wenn du KI-Systeme nicht explizit ausschließen möchtest, sollten diese Zeilen fehlen oder auf Allow stehen.
Was auf der Syntheseebene wirklich wirkt
Diese Frage wird in der Branche oft falsch beantwortet, weil die Retrieval- und Syntheseebene verwechselt werden. Für das, was das LLM aus einer abgerufenen Seite macht, gelten andere Regeln als für die Quellenauswahl.
Was KI-Chatbots auf der Syntheseebene verarbeiten:
Das Sprachmodell sieht sauberes Markdown. Es sieht Überschriftenhierarchien als strukturgebende Elemente. Es sieht Listenformate. Es sieht gut formulierten Fließtext. Es sieht Alt-Texte von Bildern. Es sieht keinen JSON-LD-Code.
Was daraus folgt:
Eine Seite, die eine Entität (Unternehmen, Person, Produkt) klar und vollständig im sichtbaren Text beschreibt, hat auf der Syntheseebene den größten Vorteil. Das ist der Kern des Grounding-Page-Ansatzes: eine dedizierte Seite, die alle relevanten Fakten zu einer Entität im sichtbaren HTML enthält und das JSON-LD diese Informationen spiegelt. Das LLM liest den Text. Google liest das Schema. Beide werden bedient.
Konkrete Maßnahmen für die Syntheseebene:
Definitorische Sätze an den Anfang von Abschnitten stellen: "Organisation X ist ein mittelständisches Beratungsunternehmen mit Schwerpunkt auf..." – solche Sätze sind ideale Zitierbausteine
Fakten im Text explizit benennen, nicht implizit lassen: Nicht "unser Team verfügt über umfangreiche Erfahrung", sondern "Carsten Feller arbeitet seit 2005 als SEO-Freelancer mit Fokus auf DACH-KMU"
Antwortbausteine strukturieren: Die PAA-Fragen (People Also Ask) zu deinem Thema direkt im Text beantworten – klar, präzise, ohne Umschweife
Inhaltliche Konsistenz: Was im JSON-LD steht, muss im sichtbaren Text stehen. Was im sichtbaren Text steht, sollte im JSON-LD gespiegelt sein. Widersprüche zwischen beiden schwächen die Quellenglaubwürdigkeit.
Optimierung für spezifische KI-Plattformen
Google AI Overviews
Besonderheiten: Nutzt Googles eigenen Search Index. Bevorzugt Websites mit etablierter Autorität und vollständigem E-E-A-T-Profil.
Strategische Maßnahmen: Vollständiges Schema.org-Markup (besonders Article, HowTo, FAQPage), klare Überschriftenstruktur, FAQ-Sektionen mit direkten Antworten, Autoren-Box mit Credentials, regelmäßige Content-Updates.
Messung: Google Search Console begann im Q2/2025 damit, Impressionen und Klicks aus KI-Suchflächen in die Performance-Metriken einzurechnen, aber diese Daten werden in den bestehenden Web-Totals zusammengeführt. Es gibt (Stand: Dokumentations-Updates Juni 2025) keine separate, dedizierte Filteranzeige "AI Overview Impressions" in der Google Search Console.
Erfahrene SEOs schauen sich besonders stark longtailige Suchanfragen an und suchen nach Auffälligkeiten bei Impressionen und Positionen, bei denen AI-Antworten zu erwarten wären.
Das kann dann so aussehen:

ChatGPT Search und SearchGPT
Besonderheiten: Nutzt Bing als Suchpartner. Bevorzugt strukturierte, faktenbasierte Inhalte mit klaren Quellen-Attributionen.
Strategische Maßnahmen: Präzise, definitorische Einleitungen, datengestützte Aussagen mit Zahlen und Statistiken, strukturierte Vergleichstabellen, Schritt-für-Schritt-Anleitungen, Glossare und Definitionen für Fachbegriffe.
Perplexity
Besonderheiten: Academic-fokussierte KI-Suche mit Schwerpunkt auf Tiefe und Quellenqualität. Bevorzugt längere, gut recherchierte Inhalte.
Strategische Maßnahmen: Tiefgehende Fachartikel (2.000+ Wörter), Quellenreferenzen mit Links, Datenvisualisierungen, sachlicher Schreibstil ohne Marketingsprache.
Zielgruppe: Perplexity-Nutzer sind typischerweise research-intensiv und hochqualifiziert. Ideal für B2B und komplexe Dienstleistungen.
Microsoft Copilot
Besonderheiten: Integration in Microsoft 365-Ökosystem. Besonders relevant für B2B-Unternehmen.
Strategische Maßnahmen: Professionelle, sachliche Sprache, Business-relevante Inhalte (Case Studies, Whitepapers, ROI-Analysen), Schema.org-Auszeichnung von ProfessionalService und Organization, LinkedIn-Präsenz.
MCP-Integration: Microsoft unterstützt seit Mai 2025 das Model Context Protocol in Copilot. Unternehmen können über MCP-Server interne Datenquellen einbinden.
Zukunftstrends und strategische Vorbereitung
Die Integration künstlicher Intelligenz in die Suche ist irreversibel. Zwischen Google AI Overviews Ankündigung (Mai 2024) und Deutschland-Rollout (März 2025) lagen zehn Monate. Zwischen AI Mode US-Start (Mai 2025) und Deutschland-Verfügbarkeit (Oktober 2025) nur fünf Monate. Diese Beschleunigung verändert strategische Planungszyklen grundlegend.
Das Model Context Protocol (MCP): Standardisierung für AI-Agenten
Im November 2024 führte Anthropic das Model Context Protocol ein, einen offenen Standard für die Verbindung von KI-Systemen mit externen Datenquellen. Die schnelle Adoption durch OpenAI (März 2025), Google DeepMind (April 2025) und Microsoft (Mai 2025) macht MCP zum aufkommenden Universal-Standard für AI-Datenintegration.
Kurz- bis mittelfristig (2025–2026): KI-Assistenten können direkt auf unternehmensinterne Datenquellen zugreifen, strukturierte Daten werden über MCP-Server bereitgestellt.
Handlungsempfehlung für KMU: MCP-Entwicklungen beobachten, aber zunächst klassische strukturierte Daten priorisieren. Die Grundlagen (Schema.org, semantisches Markup) bilden auch die Basis für MCP-Integration.
Voice Search und Smart Assistants
Strukturierte Daten sind fundamental für Voice Search-Optimierung: Google Assistant nutzt sie für direkte Antworten, Alexa greift auf Schema.org-Markups zu, Apple Siri präferiert klar strukturierte Informationen. Fokus auf lokale Informationen (Öffnungszeiten, Standort, Kontakt) und FAQ-Formate.
Multimodale KI und visuelle Suche
Multimodale Modelle wie Gemini oder GPT-4V verarbeiten Text, Bild, Video und Audio gemeinsam. ImageObject-Schema und VideoObject-Schema werden wichtiger. Investiere in hochwertige Alt-Texte, Bildbeschreibungen und Video-Transkripte.
{
"@type": "ImageObject",
"contentUrl": "https://example.com/product-image.jpg",
"description": "Detaillierte Bildbeschreibung für KI-Systeme",
"caption": "Sichtbare Bildunterschrift",
"creator": {
"@type": "Person",
"name": "Fotografenname"
}
}Häufige Fehler und wie du sie vermeidest
Eine Studie von Merkle aus 2024 analysierte 10.000 zufällig ausgewählte Websites mit strukturierten Daten: 67 Prozent wiesen mindestens einen Fehler oder eine Warnung auf. Bei 23 Prozent waren die Fehler so schwerwiegend, dass Google die strukturierten Daten komplett ignorierte.
Fehlerhafte strukturierte Daten arbeiten im Verborgenen. Die Website sieht normal aus, Rankings bleiben stabil, aber die erhofften Rich Snippets erscheinen nie. Monate können vergehen, bevor jemand bemerkt: Die Implementierung war umsonst.
Wie Google auf fehlerhafte strukturierte Daten reagiert
Bevor wir zu den konkreten Fehlerklassen kommen, ist es wichtig zu verstehen, dass Googles Reaktionen abgestuft sind und sich in drei grundlegend verschiedenen Szenarien abspielen.
Stufe 1: Ignorieren
Syntaxfehler, fehlende Pflichtfelder, unvollständige Implementierungen. Google verarbeitet das Markup schlicht nicht. Keine Benachrichtigung, kein Ranking-Effekt, keine Rich Results. Das passiert geräuschlos und bleibt oft monatelang unbemerkt.
Stufe 2: Stille Unterdrückung von Rich Results
Technisch korrektes Markup, das Googles Qualitätsansprüchen nicht genügt. Zum Beispiel ältere Inhalte ohne Relevanz-Update, schwache Domain-Autorität oder Qualitätsprobleme auf Seitenebene. Google zeigt die Rich Results nicht an, schickt aber keine Benachrichtigung und verhängt keine Strafe. Rankings bleiben unberührt.
Stufe 3: Manual Action
Eine manuelle Prüfung durch Googles Webspam-Team führt zur Verhängung einer Manual Action. Das Ergebnis: Die betroffenen Seiten verlieren die Eignung für Rich Results. Wichtig für die Einschätzung: Eine Structured-Data-Manual-Action beeinflusst in der Regel nicht, wie die Seite in der regulären Google-Websuche rankt. Es geht um die Darstellung, nicht um das Ranking.
Was eine Manual Action auslöst, ist laut Googles eigener Dokumentation eindeutig: Inhalte im JSON-LD, die für Seitenbesucher nicht sichtbar sind. Irrelevante oder irreführende Inhalte wie gefälschte Bewertungen. Markup, das nicht zum Fokus der Seite passt. Bewusste Täuschung von Nutzern.
Der entscheidende Hinweis, der in der Praxis oft unterschätzt wird: Auch ohne böse Absicht kann ein Fehler als Spam gewertet werden. Das Ausbleiben eines Manual-Action-Hinweises in der Search Console bedeutet nicht, dass alles in Ordnung ist. Qualitätsprobleme führen zu stiller Unterdrückung (Stufe 2), ohne dass du darüber informiert wirst.
Fehler 1: Inkonsistenz zwischen sichtbarem Content und strukturierten Daten
Problem: Strukturierte Daten enthalten Informationen, die für Nutzer nicht sichtbar sind, oder widersprechen dem sichtbaren Content.
Beispiel: Schema-Markup zeigt "Preis: 99 EUR", sichtbarer Preis auf der Seite ist "119 EUR".
Konsequenz: Je nach Schwere und Häufigkeit reagiert Google abgestuft. Eine veraltete Preisangabe durch fehlende Pflege führt typischerweise zur stillen Unterdrückung des Rich Results (Stufe 2). Systematisch falsche oder gezielt unsichtbar gehaltene Inhalte im Schema können eine Manual Action auslösen (Stufe 3). Die Grenze liegt nicht bei der Abweichung selbst, sondern bei der erkennbaren Absicht dahinter. Gleichzeitig ist das der kritischste Fehler für AI Visibility: Was im JSON-LD steht, aber nicht im sichtbaren Text, nutzt dem LLM ohnehin nichts.
Lösung: Automatisierte Tests implementieren, die sichtbaren Content mit Schema-Daten abgleichen. Vierteljährliche manuelle Audits. Bei dynamischen Preisen und Verfügbarkeiten: Schema-Generierung direkt aus der Datenquelle, nicht manuell gepflegt.
Fehler 2: Überoptimierung und Schema-Spam
Problem: Implementierung irrelevanter Schema-Typen in der Hoffnung auf zusätzliche Sichtbarkeit.
Beispiel: LocalBusiness-Schema auf jeder Unterseite eines Online-Shops ohne physische Präsenz.
Konsequenz: Verwässerung relevanter Signale, potenzielle Abstrafung.
Lösung: Fokus auf Qualität und Relevanz. Jedes Schema-Markup muss einen konkreten Bezug zum Seiteninhalt haben.
Fehler 3: Vernachlässigung der Wartung
Problem: Strukturierte Daten werden einmalig implementiert, aber nie aktualisiert.
Beispiel: OpeningHours-Schema zeigt veraltete Öffnungszeiten. Produkt-Preis im Schema ist veraltet.
Konsequenz: Negative Nutzererfahrung, Vertrauensverlust, potenzielle Deindexierung von Rich Snippets.
Lösung: Prozesse für automatische Updates implementieren und regelmäßige manuelle Reviews einplanen.
Fehler 4: Fehlerhafte JSON-Syntax
Problem: Syntaxfehler in JSON-LD (fehlende Kommata, falsche Anführungszeichen usw.).
{
"@context": "https://schema.org",
"@type": "Product"
"name": "Produktname"
}Konsequenz: Strukturierte Daten werden komplett ignoriert.
Lösung: Obligatorischer JSON-Validator in der Deployment-Pipeline. Keine Veröffentlichung ohne erfolgreiche Validierung.
Fehler 5: Fehlende @context und @type Deklarationen
Problem: Unvollständige Schema-Markups ohne grundlegende Type-Definition.
Beispiel:
{
"name": "Produktname",
"price": "99"
}Konsequenz: Suchmaschinen können das Markup nicht interpretieren.
Lösung: Jedes JSON-LD-Objekt muss "@context" und "@type" enthalten.
Fazit und strategische Handlungsempfehlungen
Strukturierte Daten haben sich von einem technischen SEO-Detail zu einem strategischen Faktor entwickelt. In einer Ära, in der 60 Prozent der Suchen ohne Klick enden und KI-Systeme zunehmend als Gatekeeper zwischen Content und Nutzer agieren, ist maschinenlesbare Datenstrukturierung unverzichtbar. Allerdings mit einem klaren Verständnis dafür, auf welcher Ebene sie wirkt.
Kernerkenntnisse:
JSON-LD und Googlebots Knowledge Graph: Direkter, deterministischer Effekt. Hier ist JSON-LD unverzichtbar und wirkt messbar über Rich Results und Knowledge Panels.
JSON-LD und KI-Chatbots: Indirekter Effekt über den klassischen Suchindex. LLMs filtern alle script-Tags beim Seitenabruf heraus. Das JSON-LD wird verworfen, bevor der Text das Sprachmodell erreicht.
Was auf der Syntheseebene zählt: Sichtbarer Text mit klarer Struktur. Definitorische Aussagen. Faktenbasierter Inhalt. Eine Seite, die alle relevanten Informationen im HTML-Text explizit nennt, hat einen entscheidenden Vorteil gegenüber einer Seite, die sich auf unsichtbares Markup verlässt.
Das Prinzip vollständiger Spiegelung: Alles, was im JSON-LD steht, muss im sichtbaren Text stehen. Das ist kein optionaler Zusatz, sondern die Voraussetzung dafür, dass beide Ebenen funktionieren.
Fokus auf Qualität und Relevanz: Fünf perfekt implementierte, geschäftsrelevante Schema-Typen bringen mehr als 50 oberflächliche Markups.
Handlungsempfehlungen nach Unternehmensgröße
Kleinstunternehmen (1–10 Mitarbeiter, begrenzte Ressourcen)
Priorisierung: LocalBusiness-Schema (falls lokal), Organization-Schema, FAQ-Schema auf 3–5 Kernseiten, Google Business Profile optimieren. Investition: 500–1.000 EUR für initiale Implementierung (extern) oder 2–3 Tage interner Aufwand mit Plugin.
Kleine Unternehmen (10–50 Mitarbeiter, dedizierte Marketing-Ressource)
Priorisierung: Alle Basis-Schemas (Organization, LocalBusiness, Product/Service), Blog-Content mit Article- und Person-Schema, FAQ und HowTo auf relevanten Seiten, vollständiges E-E-A-T-Profil (Autoren, Credentials), systematisches Review-Management. Investition: 2.000–5.000 EUR.
Mittelständische Unternehmen (50–250 Mitarbeiter, dediziertes Marketing-Team)
Priorisierung: Vollständige Schema-Implementierung über alle relevanten Seitentypen, dynamische strukturierte Daten für E-Commerce, Advanced Features (VideoObject, ImageObject, Event), Knowledge Panel-Strategie (Wikidata, externe Autorität), MCP-Readiness evaluieren.
Der Weg nach vorne
Die Integration künstlicher Intelligenz in die Suche ist irreversibel. Unternehmen, die heute in strukturierte Daten und AI-Search Optimization investieren, positionieren sich für die nächste Dekade der digitalen Sichtbarkeit.
Der entscheidende Punkt ist nicht, ob du strukturierte Daten implementierst. Die entscheidende Frage ist, ob du verstehst, auf welcher Ebene sie wirken. Wer JSON-LD als direkten Hebel für KI-Chatbot-Zitierungen betrachtet, optimiert für ein Verhalten, das technisch so nicht existiert. Wer es als Teil einer ganzheitlichen Strategie aus sauberem Schema, klassisch starken Rankings und inhaltlich präzisem sichtbarem Text begreift, hat eine solide Grundlage.
Empfohlener erster Schritt: Führe ein Audit deiner strukturierten Daten durch, nutze den Google Rich Results Test, und überprüfe dabei, ob alle im JSON-LD enthaltenen Informationen auch im sichtbaren Seitentext vorhanden sind. Was in beiden Ebenen konsistent und präzise steht, funktioniert für Googlebot direkt und für das LLM indirekt über den klassischen Suchindex.
FAQ Strukturierte Daten / JSON-LD
-
Helfen strukturierte Daten dabei, in KI-Suchmaschinen zitiert zu werden?
Indirekt, ja. JSON-LD verbessert die klassischen Suchmaschinen-Rankings einer Seite. KI-Systeme wie ChatGPT oder Perplexity wählen ihre Quellen über klassische Suchindizes (Google, Bing) aus. Eine besser positionierte Seite hat damit eine höhere Chance, als Quelle ausgewählt zu werden. Was das Sprachmodell dann aus der abgerufenen Seite macht, basiert ausschließlich auf dem sichtbaren Textinhalt, nicht auf dem JSON-LD-Code.
-
Lesen KI-Chatbots wie ChatGPT oder Perplexity JSON-LD Daten?
Nein. Standard-RAG-Pipelines und HTML-to-Text-Parser wie Trafilatura oder Mozilla Readability.js filtern alle script-Tags aktiv heraus, bevor der Text das Sprachmodell erreicht. JSON-LD wird verworfen, weil komplexe JSON-Syntax Token im Kontextfenster des Modells verschwendet, ohne semantischen Mehrwert zu liefern. Das Sprachmodell sieht sauberes Markdown aus dem sichtbaren Seitentext.
-
Was ist der Unterschied zwischen Googlebot und KI-Crawlern beim Umgang mit strukturierten Daten?
Googlebot arbeitet deterministisch: Er liest JSON-LD nach festen Regeln wie einen Datenbankimport und speist die Daten direkt in den Knowledge Graph ein. KI-Crawler sind probabilistische Textgeneratoren: Sie extrahieren beim Seitenabruf nur den sichtbaren Text in Markdown-Format und verwerfen alle script-Tags inklusive JSON-LD. Beide Systeme beginnen allerdings mit einem klassischen Suchindex, in dem JSON-LD über bessere Rankings indirekt wirkt.
-
Welche Schema-Typen sind für kleine und mittelständige Unternehmen am wichtigsten?
Die Basis bilden Organization oder LocalBusiness (für Unternehmensseiten), Article mit Person-Markup für Autoren (für Blogbeiträge und Fachartikel) sowie Product mit Offer und AggregateRating (für E-Commerce). Für B2B-Unternehmen sind ProfessionalService und Event relevant. Fünf sauber implementierte, zum Geschäftsmodell passende Schema-Typen bringen mehr als 50 oberflächliche Markups.
-
Was wirkt auf der Syntheseebene von KI-Systemen wirklich, wenn nicht JSON-LD?
Was das Sprachmodell verarbeitet, ist der sichtbare Text in Markdown-Format. Entscheidend sind klare Überschriftenhierarchien, die den Parser-Prozess überleben, definitorische Aussagen zu Beginn von Abschnitten, faktenbasierter Inhalt mit konkreten Angaben sowie strukturierte Listen statt Fließtext-Aufzählungen. Das Prinzip vollständiger Spiegelung gilt: Alles, was im JSON-LD steht, sollte auch im sichtbaren Seitentext stehen. Was das LLM nicht im sichtbaren Text findet, findet es nirgends.
-
Sind FAQ-Schema nach den Änderungen von 2023 noch sinnvoll?
Ja. Seit August 2023 spielt Google FAQ Rich Snippets für die meisten Websites nicht mehr aus, beschränkt auf autoritative Regierungs- und Gesundheitsseiten. Das FAQPage-Schema bleibt aber sinnvoll, weil es Googles semantisches Verständnis einer Seite verbessert, weiterhin nicht zu den im Januar 2026 deprecateten Schema-Typen gehört und von KI-Suchen über den klassischen Index indirekt berücksichtigt wird.
Weitere AI-Search Optimierung Themen
Wenn du die Analyse nicht selbst machen willst oder einen zweiten Blick auf dein Setup brauchst:
Ich biete das als eigenständiges Paket "Schema Markup Konzept" an. Dieses Modul liefert ein vollständiges Markup-Konzept, keine generischen Empfehlungen, sondern ein auf deine spezifischen Inhaltstypen zugeschnittenes Dokument.