Direct Traffic in GA4: Analyse, Diagnose und Optimierung
Direct Traffic gilt als einfachste Metrik im Analytics-Cockpit. In der Praxis ist (direct) / (none) ein Sammelbecken für alles, was GA4 nicht zuordnen kann. Wer das nicht weiß, optimiert auf Basis von Datenlücken.

Direct Traffic gilt als das Schönste, was einer Website passieren kann. Lauter treue Nutzer, die direkt tippen. In der Praxis ist der Kanal (direct) / (none) in Google Analytics 4 aber häufig etwas ganz anderes: Ein Sammelbecken für alles, was GA4 nicht zuordnen kann. Wer das nicht weiß, trifft Budgetentscheidungen auf Basis von Datenlücken.
Dieser Leitfaden zeigt, was sich wirklich hinter dem Direct-Kanal verbirgt, wie du echten von fehlerhaft zugewiesenem Traffic trennst, welche Rolle Datenschutztechnologien dabei spielen und warum die Verbindung zu SEO indirekter ist, als viele annehmen.
Das Missverständnis des direkten Traffics
Die landläufige Definition ist schnell erklärt: Besucher, die eine URL direkt eintippen oder ein Lesezeichen verwenden. Das klingt sauber und messbar. Die Realität ist eine andere.
Der Kanal (direct) / (none) in GA4 ist keine klar definierte Zugangsart, sondern eine Fallback-Kategorie: Jede Sitzung, deren Herkunft GA4 nicht einem anderen Kanal zuordnen kann, landet hier. Das umfasst echte direkte Zugriffe, aber auch Traffic aus WhatsApp-Links, Desktop-E-Mail-Clients, PDFs, App-internen Browsern und fehlerhaft konfigurierten Kampagnen.
Die Konsequenz ist nicht trivial. Wer einen Anstieg im Direct-Kanal als Zeichen wachsender Markenbekanntheit feiert, während in Wirklichkeit UTM-Parameter in der letzten E-Mail-Kampagne gefehlt haben, kürzt im nächsten Schritt das E-Mail-Budget, weil es ja "offenbar wenig bringt".
Ein hoher Direct-Traffic-Anteil ist deshalb vor allem eines: Ein diagnostisches Signal. Es lohnt sich, genauer hinzusehen.
Die Anatomie von (direct) / (none) in GA4
Die technische Grundlage
GA4 klassifiziert eine Sitzung als (direct) / (none), wenn kein HTTP-Referrer vorhanden ist und keine UTM-Parameter mitgeliefert wurden. Der HTTP-Referrer ist ein technischer Header, den ein Browser an die Zielseite sendet; er enthält die URL der vorherigen Seite. Fehlt dieser Header, weiß GA4 schlicht nicht, woher der Besuch kam, und setzt ihn in die Standardkategorie.
Das erklärt, warum so viele unterschiedliche Besuchstypen in einem einzigen Kanal landen. GA4 hat keine andere Wahl.
Direct als Auffangbecken
Eine verbreitete Fehlvorstellung ist, dass die Kanäle in GA4 saubere, voneinander getrennte Datentöpfe sind. Sie sind es nicht. In der Praxis sind diese Kanäle durchlässig, und der Direct-Kanal absorbiert die Lecks aus allen anderen.
Als grobe Orientierung gilt: Ein Direct-Anteil von 5 bis 20 Prozent ist für die meisten Websites plausibel. Alles darüber, insbesondere jenseits von 25 Prozent, deutet mit hoher Wahrscheinlichkeit auf Tracking-Lücken hin statt auf überragende Markenbekanntheit.
Ein plötzlicher Spike im Direct-Kanal sollte die Frage auslösen: Welcher andere Kanal ist zeitgleich und unerwartet eingebrochen? Der Anstieg ist dann nicht das Problem, sondern das Symptom.
Die zwei Kategorien
Jede Analyse von Direct Traffic beginnt mit einer Grundunterscheidung:
1. Echter Direct Traffic sind Besuche, die tatsächlich auf Markenbekanntheit und bewusster Nutzerentscheidung beruhen: manuelle URL-Eingabe, gespeicherte Lesezeichen, Browser-Autofill. Dieser Traffic ist ein echtes Markensignal und wertvoll.
2. Dark Traffic umfasst alle Besuche, die eigentlich aus anderen Kanälen stammen, aber ihre Quellinformationen unterwegs verloren haben. Er verzerrt die Analyse aller anderen Kanäle und macht deren Performance unsichtbar.
Die Fähigkeit, diese beiden Komponenten zu trennen, ist der Kern sauberer Attribution.
Abgrenzung zu „Unassigned" Traffic
Wer beides verwechselt, repariert die falsche Baustelle.
Direct Traffic entsteht durch fehlende Herkunftsdaten: GA4 hat keine Quelle empfangen.
Unassigned Traffic ist ein Klassifizierungsfehler innerhalb GA4: Eine Quelle ist vorhanden, passt aber zu keiner der vordefinierten Kanalgruppen. Das liegt fast immer an falschem UTM-Tagging.
Typische Fehler:
❌ Falsch: utm_medium=mail
✅ Richtig: utm_medium=email
❌ Falsch: utm_source=stape&utm_medium=sst
✅ Richtig: utm_source=newsletter&utm_medium=email
Weitere Ursachen für Unassigned: fehlerhafte Weiterleitungen, GTM-Probleme, fehlende session_start-Events, Ad-Blocker-Interferenzen.
Die wahren Quellen des Direct Traffic
Echter Direct Traffic: Markenbekanntheit in Zahlen
Manuelle URL-Eingaben und Lesezeichen sind das, was Marketer sich wünschen. Sie zeigen, dass Nutzer eine Marke so gut kennen, dass sie den Umweg über Google für überflüssig halten.
Besonders relevant ist die Verbindung zu Offline-Maßnahmen. TV, Print, Radio, Events: Keiner dieser Kanäle liefert klickbare Links. Der typische nächste Schritt nach einer TV-Kampagne ist die direkte Eingabe der beworbenen Domain. Ein messbarer Anstieg im Direct-Kanal nach Kampagnenstart ist ein handfester Indikator für deren Wirkung, wenngleich kein präziser.
Dark Traffic: Das Mysterium der fehlenden Referrer
Dark Traffic ist der Oberbegriff für alles, was eigentlich einem anderen Kanal zugehört, aber auf dem Weg zur Website seinen Referrer verloren hat. Der Begriff „Dark Social" deckt dabei den größten Anteil ab.
Dark Social bezeichnet geteilte Links über private oder geschlossene Kommunikationskanäle: WhatsApp, Telegram, Signal, Facebook Messenger, Instagram DMs, LinkedIn DMs, Slack, Microsoft Teams. Wenn jemand einen Artikel-Link in einer dieser Umgebungen teilt und der Empfänger daraufklickt, sendet der Browser in der Regel keinen Referrer. GA4 sieht nur: neuer Besuch, keine Quelle.
Schätzungen zufolge findet ein erheblicher Teil des Content-Sharings in diesen privaten Kanälen statt. Eine exakte Zahl ist hier bewusst nicht angegeben, da verlässliche Studien zu diesem spezifischen Anteil rar sind. Klar ist: Es ist viel, und es wächst.
Mobile Apps verschärfen das Problem. Facebook, Instagram, TikTok und andere Social Apps öffnen externe Links oft in einem App-internen Browser. Diese In-App-Browser blockieren häufig Referrer-Daten, entweder aus Datenschutzgründen oder um Nutzer im eigenen Ökosystem zu halten. Ein Klick auf einen Link in der Instagram-App kann in GA4 als direkter Besuch erscheinen, obwohl er aus einem Social-Post stammt.
Technische Ursachen kommen hinzu:
- HTTPS zu HTTP: Wenn ein Nutzer von einer sicheren (HTTPS) auf eine unsichere (HTTP) Seite wechselt, blockiert der Browser die Referrer-Übermittlung. Das ist kein Bug, sondern ein bewusster Sicherheitsmechanismus.
- Fehlender Tracking-Code auf einzelnen Seiten: Fehlt der GA4-Tag auf einer Landingpage, registriert GA4 den ersten Besuch nicht. Wenn der Nutzer von dort auf eine getaggte Seite wechselt, erscheint die eigene Domain als Referrer. Da die eigene Domain in der Verweisausschlussliste steht, wird dieser sogenannte Self-Referral als Direct Traffic klassifiziert.
- Fehlerhafte Weiterleitungen: Clientseitige JavaScript-Weiterleitungen (
window.location.href) und komplexe Weiterleitungsketten können UTM-Parameter und Referrer-Informationen schlucken. Serverseitige 301-Redirects sind robuster. - Links aus Offline-Dokumenten: Klicks auf Hyperlinks in PDFs, Word-Dateien, Excel-Tabellen oder PowerPoint-Präsentationen senden keinen Referrer. Ohne UTM-Parameter landet dieser Traffic als Direct.
- Referrer Policy: Verweisende Seiten können über einen Meta-Tag oder HTTP-Header steuern, welche Referrer-Informationen sie weitergeben. Restriktive Einstellungen wie
no-referrerbedeuten für die Zielseite: kein Referrer, kein Kanal, Direct.
AI-Suche als neue Quelle von Dark Traffic: Das ist ein Punkt, der in den meisten Guides noch fehlt. Wenn Nutzer über KI-generierte Antworten in ChatGPT, Perplexity, Google AI Overviews oder anderen Systemen auf eine Website gelangen, fehlt in vielen Fällen ein auswertbarer Referrer. Diese Besuche können als Direct Traffic erscheinen oder in „Unassigned" landen, je nach Implementierung des Systems. Mit wachsendem AI-Search-Traffic wird dieser blinde Fleck relevanter.
Tabelle: Quellen des Direct Traffic - Kategorisierung und Diagnose
| Quelle | Kategorie | Typische GA4-Indikatoren | Lösungsansatz |
|---|---|---|---|
| Manuelle URL-Eingabe | Echter Direct Traffic | Landingpage meist Startseite (/), hoher Anteil wiederkehrender Nutzer | Markenaufbau, einprägsame Domain, Offline-Marketing |
| Lesezeichen / Browser-Autofill | Echter Direct Traffic | Landingpages oft tiefe, nützliche Seiten (Login, Tools, Blogartikel), hohe Engagement-Rate | „Bookmark-würdigen" Content schaffen, UX optimieren |
| Dark Social (WhatsApp, Messenger etc.) | Dark Traffic | Unvorhersehbare Spikes, sehr spezifische Landingpages, hoher mobiler Anteil | Konsequent UTM-Parameter für alle geteilten Links verwenden |
| E-Mail-Clients (z.B. Outlook) | Dark Traffic | Spikes korrelieren zeitlich mit Kampagnenversand, Rückgang im E-Mail-Kanal | Alle Links in E-Mail-Kampagnen zwingend mit UTMs versehen |
| Mobile App-Browser | Dark Traffic | Hoher mobiler Anteil im Direct-Kanal, Landingpages entsprechen beworbenen Inhalten | UTM-Parameter in Social-Media-Profilen und Posts |
| HTTPS → HTTP-Übergang | Technischer Fehler | Referral-Traffic von HTTPS-Partnerseiten fehlt | Vollständige HTTPS-Migration, alle internen Links auf HTTPS prüfen |
| Fehlender Tracking-Code | Technischer Fehler | Landingpage (not set), Self-Referral von eigener Domain | Regelmäßige technische Audits, GA4-Tag auf jeder Seite überprüfen |
| Fehlerhafte Weiterleitungen | Technischer Fehler | Referrer-Verlust nach Website-Änderungen, Zielseiten von Redirects | Alle Redirect-Ketten auditieren, serverseitige 301-Redirects bevorzugen |
| Links in PDFs, Word, etc. | Dark Traffic | Traffic auf in Offline-Materialien beworbene Seiten | UTM-getaggte Links in allen nicht-webbasierten Dokumenten |
| AI-Suchsysteme (Perplexity, AI Overviews etc.) | Dark Traffic (wachsend) | Unstrukturierter Anstieg, keine erkennbare Quelle, variiert je nach System | llms.txt, strukturierte Daten, UTM-Parameter in verlinkten Inhalten |
Datenschutztechnologien und ihre Auswirkungen auf die Attribution
Die Tracking-Landschaft wird seit Jahren durch Datenschutzvorgaben und Browser-Entscheidungen umgebaut. Das Ergebnis: Saubere Attribution wird strukturell schwieriger, und der Anteil des nicht zuordenbaren Traffics nimmt zu.
Apple ITP (Intelligent Tracking Prevention)
Apple hat mit dem Safari-Browser eine konsequente Anti-Tracking-Position eingenommen. Die Auswirkungen gehen über das Blockieren von Drittanbieter-Cookies weit hinaus.
ITP schränkt die Lebensdauer clientseitig gesetzter Cookies (über JavaScript) massiv ein: standardmäßig 7 Tage, unter bestimmten Umständen auf 24 Stunden. Zusätzlich verfügt ITP über eine Link Tracking Protection, die bekannte Tracking-Parameter wie gclid von Google Ads oder fbclid von Facebook automatisch aus URLs entfernen kann.
Das verfälscht nicht nur Attribution, sondern auch die Metriken. „Neue Nutzer" werden systematisch überschätzt, „Wiederkehrende Nutzer" unterschätzt.
Google Consent Mode und Cookie-Banner
Seit der DSGVO ist Tracking ohne Einwilligung in Deutschland und der EU eingeschränkt. Wenn ein Nutzer den Analytics-Cookies widerspricht (analytics_storage='denied'), setzt GA4 keine identifizierenden Cookies mehr. Stattdessen sendet GA4 anonymisierte Aggregate, sogenannte Cookieless Pings, ohne individuelle Nutzerkennung.
Google versucht, die entstehenden Datenlücken durch statistische Modellierung zu schließen: Verhaltensmodelle schätzen das Verhalten nicht zustimmender Nutzer auf Basis ähnlicher, zustimmender Nutzer. Das ist besser als nichts, aber es sind Schätzungen, keine Messungen.
Auswirkungen auf Direct Traffic: Wenn ein Nutzer ohne Zustimmung auf die Website gelangt, beispielsweise durch einen Klick auf ein organisches Suchergebnis, wird die Kette zwischen der Quelle (Google Suche) und der Sitzung auf der Website unterbrochen. GA4 kann den Besuch keiner spezifischen Quelle mehr sicher zuordnen. Obwohl die Verhaltensmodellierung versucht, diese Lücken zu füllen, kann dies, insbesondere in der Anfangsphase, bevor die Modelle ausreichend trainiert sind, zu einem Anstieg von nicht zuordenbarem und somit als "Direct" klassifiziertem Traffic führen. Die Genauigkeit der Attributionsdaten leidet, und die Abhängigkeit von modellierten statt gemessenen Daten steigt.
Wenn ein Nutzer ohne Einwilligung über ein organisches Suchergebnis auf eine Seite kommt, kann GA4 diesen Besuch keiner Quelle mehr sicher zuordnen. Das Resultat: ein weiterer Beitrag zum Direct-Kanal, diesmal durch Datenschutz-Compliance verursacht.
Server-Side Tagging: strukturelle Antwort auf strukturelle Probleme
Angesichts dieser Entwicklungen bekommt serverseitiges Tagging zunehmend strategische Bedeutung. Das Grundprinzip ist ein Architekturwechsel in der Datenerfassung.
Client-Side Tagging (Standardansatz): Der Browser des Nutzers kommuniziert direkt mit Google, Facebook und anderen Drittanbietern. Jeder Tag auf der Website stellt eine separate Verbindung her. Ad-Blocker, ITP und andere clientseitige Mechanismen können diese Verbindungen blockieren oder manipulieren.
Server-Side Tagging: Der Browser sendet nur noch eine einzige Datenanfrage an einen selbst kontrollierten Server-Container (z.B. in der Google Cloud Platform). Dieser Server empfängt die Daten, verarbeitet sie und leitet sie nach definierten Regeln an Drittanbieter weiter.
Der entscheidende Vorteil ist nicht nur technisch. Serverseitig gesetzte HTTP-Cookies unterliegen nicht den ITP-Beschränkungen und haben längere Laufzeiten. Mehr Daten können zugeordnet werden, der Direct-Kanal schrumpft auf ein realistischeres Maß.
Die Kehrseite: Server-Side Tagging ist komplex und verursacht laufende Infrastrukturkosten. Für große Websites mit Paid-Budget lohnt sich die Investition klar. Für kleine Websites ohne Kampagnen-Traffic ist es Overkill.
Tabelle: Client-Side- vs. Server-Side-Tagging
| Kriterium | Client-Side (Browser) | Server-Side (Server) |
|---|---|---|
| Website-Geschwindigkeit | Potenziell langsamer durch viele JS-Tags im Browser | Schneller, da weniger Client-seitiger Code |
| Datenkontrolle | Gering; Browser sendet direkt an Drittanbieter | Vollständige Kontrolle; Daten können vor Weitergabe bereinigt werden |
| Tracking-Genauigkeit | Anfällig für Ad-Blocker, ITP und Browser-Restriktionen | Deutlich robuster gegenüber clientseitigen Blockern |
| Cookie-Lebensdauer | JS-Cookies durch ITP auf 7 Tage / 24h begrenzt | HTTP-Cookies ohne ITP-Beschränkung, längere Laufzeit |
| Implementierungskomplexität | Einfach, viele Plug-and-Play-Lösungen | Komplex; erfordert technisches Know-how und Server-Infrastruktur |
| Kosten | Meist kostenlos (abgesehen von Tag-Management-Systemen) | Laufende Cloud-Kosten, variabel je nach Traffic-Volumen |
Beispiel-Tools für DACH: Was konkret funktioniert
Der einfachste Einstieg in Server-Side Tagging läuft für die meisten Websites über den Server-seitigen Google Tag Manager (sGTM) in Kombination mit einem Hosting-Service. Den Container selbst auf der Google Cloud Platform zu betreiben ist technisch möglich, kostet aber bei moderatem Traffic erfahrungsgemäß rund 120 US-Dollar pro Monat für eine produktionstaugliche Mindestinfrastruktur (drei Instanzen, Autoscaling, Logs). Deutlich zugänglicher sind spezialisierte Hosting-Dienste.
Stape.io ist der international meistgenutzte Anbieter für sGTM-Hosting und ab 20 US-Dollar pro Monat einsetzbar. Stape ist ein US-Unternehmen, betreibt aber eine eigene europäische Gesellschaft und hostet DACH-Kunden auf EU-Servern (EU Center Deutschland, EU West Belgien). Für die DSGVO-Konformität ist der EU-Serverstandort notwendig, aber nicht hinreichend: Die Datenkonfiguration im Container muss ebenfalls stimmen.
Wer eine vollständig europäische Lösung ohne US-Unternehmenshintergrund bevorzugt, sollte JENTIS prüfen. JENTIS ist ein österreichischer Anbieter mit eigenem Tag Manager, der vollständig auf EU-Infrastruktur läuft und eine sogenannte Twin-Server-Technologie mitbringt, die in einigen Szenarien höhere Nutzererfassungsraten als Stape erreicht. Der Preis ist deutlich höher und richtet sich eher an mittlere bis größere Websites mit ernsthaftem Paid-Budget.
Für rein deutsche Infrastruktur ohne GTM: etracker ist eine Hamburger Lösung, die einwilligungsfreie Web-Analyse, serverseitiges Conversion Tracking und Tag Management in einem Produkt vereint. Das ist ein anderer Ansatz als sGTM-Hosting, kann aber für Websites sinnvoll sein, die ohnehin über einen GA4-Wechsel nachdenken.
Wann lohnt sich der Aufwand? Die gängige Faustregel: monatliches Paid-Budget über 3.000 bis 5.000 Euro, oder messbare Datenlücken durch hohen Safari-Anteil, oder spürbare Ad-Blocker-Verluste. Wer kein aktives Paid-Kampagnen-Setup betreibt und GA4 primär zur organischen Traffic-Analyse nutzt, erhält durch SST weniger Mehrwert, weil die Attribution bei Paid-Kanälen der größte Gewinn ist.
Strategische Analyse von Direct Traffic in GA4
Die Analyse von Direct Traffic ist weniger Wissenschaft als Detektivarbeit. Es geht darum, Indizien zu sammeln und die wahrscheinlichste Erklärung für Datenmuster zu finden.
Im Berichte-Bereich
Der Standardbereich "Berichte" in GA4 ist der erste Anlaufpunkt für eine schnelle Diagnose.
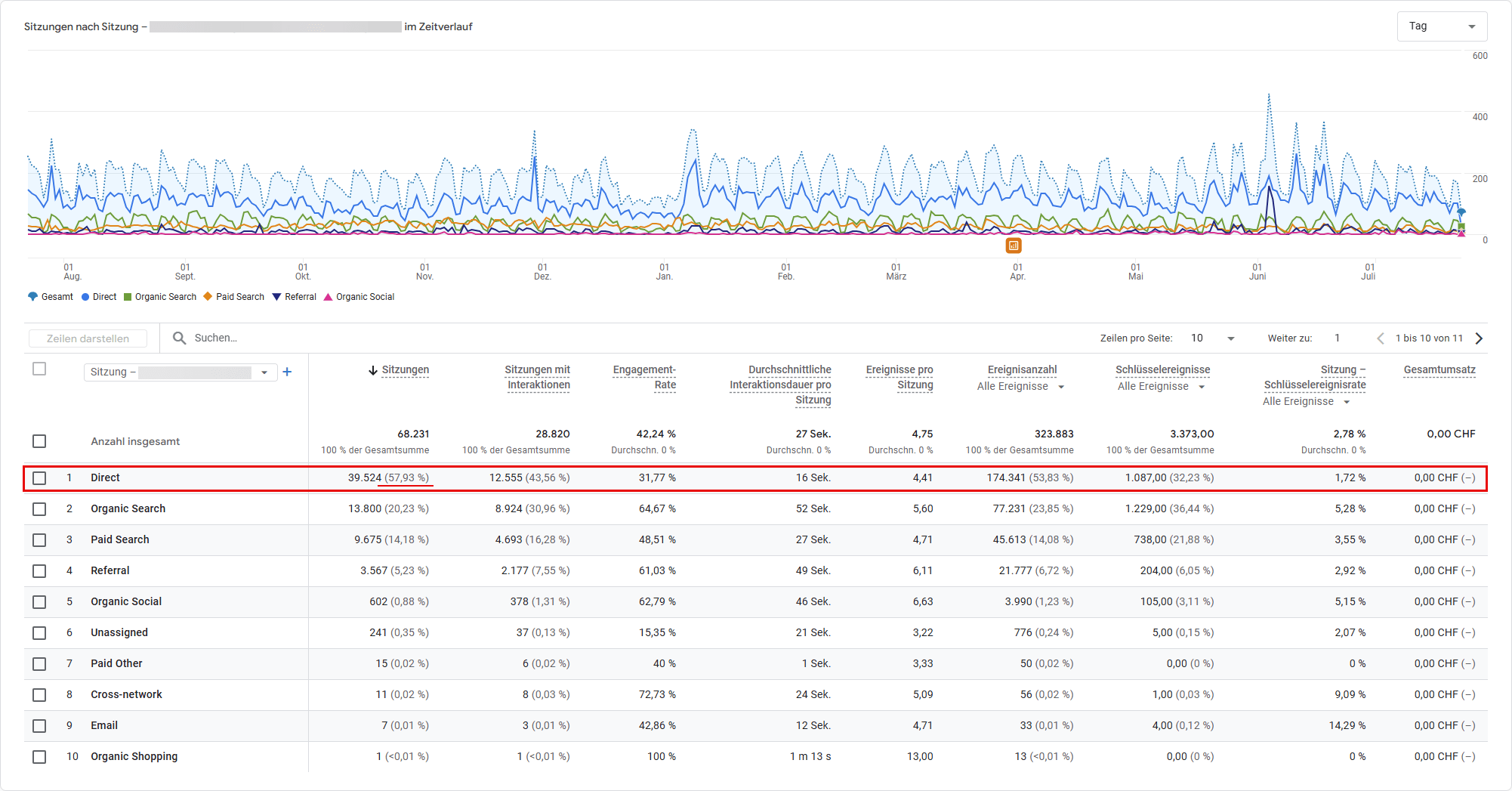
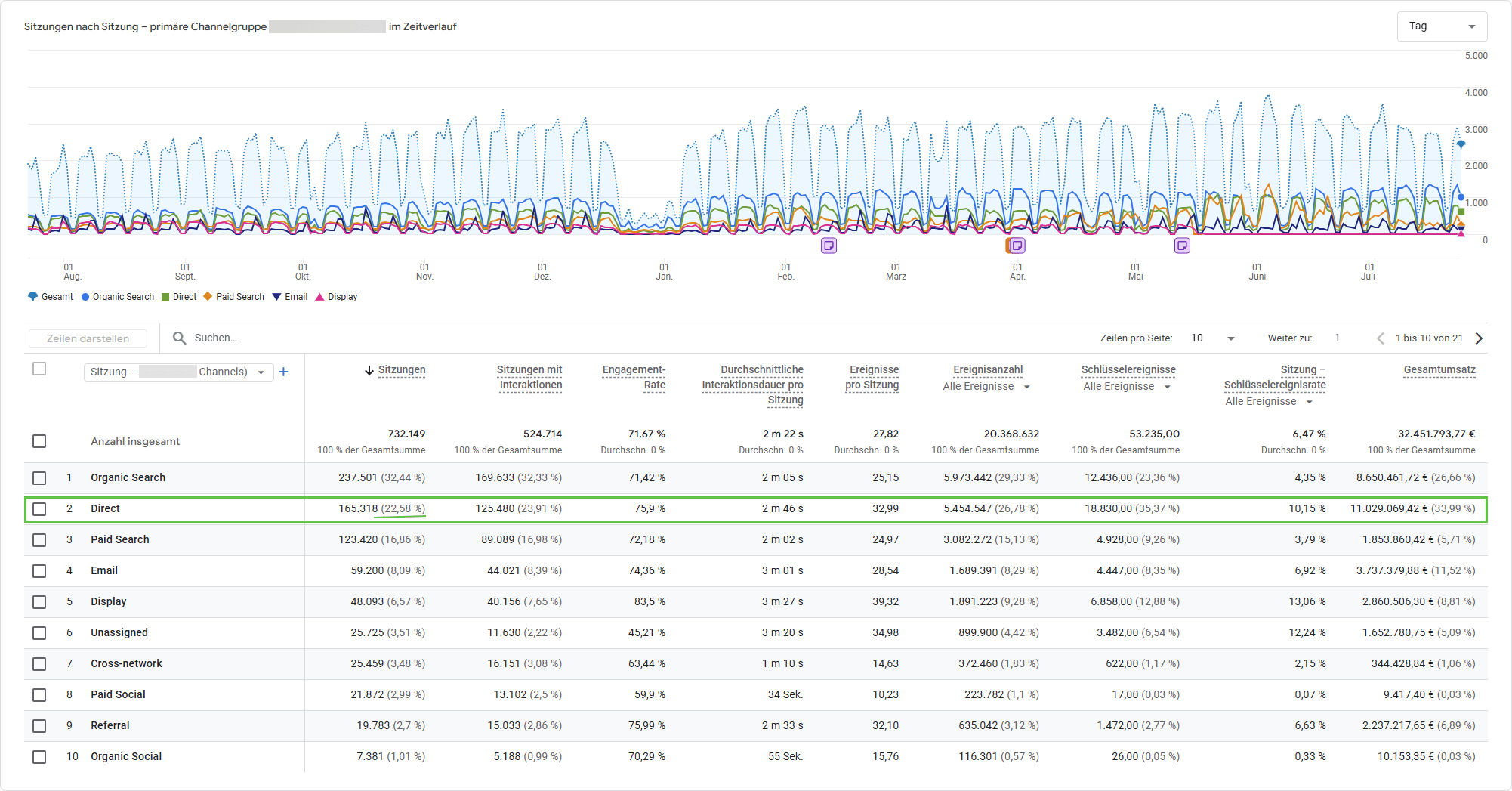
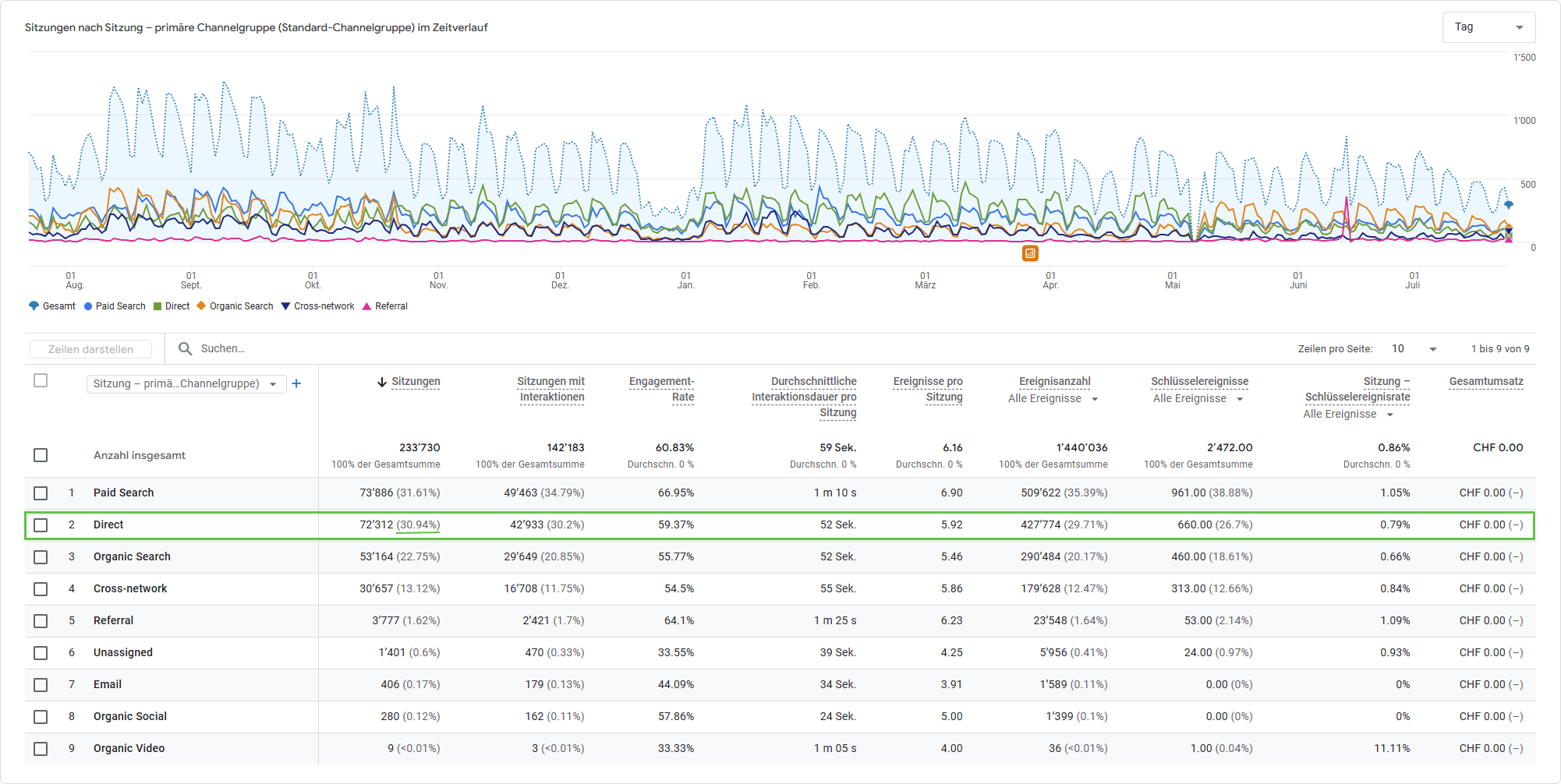
Der Ausgangspunkt ist der Traffic-Akquise-Bericht (Berichte > Akquisition > Traffic-Akquisition). Die primäre Dimension Sitzung: Standard-Channelgroup zeigt den prozentualen Direct-Anteil. Liegt er über 20 bis 25 Prozent, lohnt sich eine tiefere Analyse.
Die eigentlich relevanten Erkenntnisse kommen durch sekundäre Dimensionen:
- Landingpage + Abfragestring: Das ist die wichtigste Dimension zur Entschlüsselung von Direct Traffic. Ein direkter Besuch auf der Startseite (
/) ist plausibel. Ein direkter Besuch auf/blog/2024/07/ein-sehr-spezifischer-langer-artikel/ist es nicht. Wer tippt solche URLs manuell ein? Niemand. Das ist Dark Traffic, dessen Quelle abgeschnitten wurde. - Gerätekategorie: Ein überproportional hoher mobiler Anteil im Direct-Segment deutet auf Traffic aus mobilen Apps hin.
- Browser: Auffällig viel Safari im Direct-Segment? Erster Verdacht: ITP-Auswirkungen.
- Land: Ein plötzlicher Spike aus einem bestimmten Land kann auf Bot-Traffic hindeuten, aber auch auf eine erfolgreiche regionale Kampagne.
Explorative Datenanalysen
Für tiefere Einblicke bieten die Explorations in GA4 mehr Flexibilität. Der Kern der Methode: Ein Segment erstellen, das ausschließlich Sitzungen aus dem Direct-Kanal enthält (Sitzung: Standard-Channelgroup = Direct), und dieses Segment mit dem Verhalten anderer Kanäle vergleichen.
Sinnvolle Vergleichsmetriken:
- Engagement-Rate und durchschnittliche Interaktionsdauer: Sind direkte Besucher signifikant engagierter? Das wäre ein starkes Zeichen für echte Markenloyalität.
- Conversions (Schlüsselereignisse): Höhere Conversion-Rate bei Direct Traffic? Diese Nutzer befinden sich oft weit unten im Funnel und haben klare Kaufabsicht.
- Trichter-Exploration: Wo steigen direkte Besucher in einen Conversion-Funnel ein, und wo brechen sie ab?
Korrelation als Diagnosemethode
Viele Quellen von Direct Traffic, vor allem Offline-Maßnahmen und Dark Social, sind per Definition nicht direkt messbar. Die einzige praktische Methode ist Korrelationsanalyse über Zeit.
Das Prinzip: Direct-Traffic-Verlauf visualisieren und die Start- und Enddaten aller Marketingaktivitäten einzeichnen. Ein Spike, der zeitlich eng mit dem Versand eines Newsletters oder dem Start einer TV-Kampagne übereinstimmt, ist kein Zufall.
Einen Marketingkalender zu führen und darin alle Kampagnenstarts, PR-Aktivitäten und Offline-Events zu protokollieren, ist deshalb kein Nice-to-have, sondern eine Grundvoraussetzung für valide Attribution.
Das gilt übrigens auch für SEO-Maßnahmen und technische Website-Änderungen. Viele SEO-Tools bieten die Möglichkeit, Notizen zu bestimmten Zeitpunkten zu hinterlegen. Ein Sichtbarkeitsverlust nach einem Serverwechsel lässt sich so deutlich einfacher der wahrscheinlichen Ursache zuordnen.
Leitfaden zur Reduzierung von Dark Traffic
Das Ziel ist nicht, Direct Traffic auf null zu drücken. Ein gesunder Anteil an echtem Direct Traffic ist wünschenswert. Das Ziel ist, den unbekannten, fehlerhaft zugeordneten Anteil zu minimieren, um ein realistisches Bild der Marketingleistung zu erhalten.
UTM-Parameter: Die erste Verteidigungslinie
UTM-Parameter sind kurze Code-Schnipsel am Ende einer URL, die GA4 explizit mitteilen, woher ein Klick stammt. Sie machen die Abhängigkeit vom HTTP-Referrer überflüssig.
Die fünf Parameter im Überblick:
utm_source: Die spezifische Herkunftsplattform (z.B.google,facebook,newsletter_jul25,partner_blog)utm_medium: Der Marketing-Kanal (z.B.cpc,organic_social,email,affiliate)utm_campaign: Die spezifische Kampagne (z.B.winter_sale_2025,product_launch_q3)utm_term(optional): Das Keyword bei bezahlter Sucheutm_content(optional): Zur Differenzierung von Creatives innerhalb einer Kampagne (z.B.blue_buttonvs.text_link)
Goldene Regel: UTM-Parameter für alle externen Marketing-Links verwenden, deren Performance gemessen werden soll. Konkret: alle Links in E-Mail-Kampagnen, in Social-Media-Posts und Profilen, in QR-Codes auf Printmaterialien, in herunterladbaren PDFs und Präsentationen, und in Affiliate- oder Partnerlinks.
Wichtige Ausnahme: Interne Links innerhalb der eigenen Website dürfen niemals mit UTM-Parametern versehen werden. Wer das trotzdem tut, überschreibt die ursprüngliche Sitzung des Nutzers und zerstört die Attributionskette. Ein Nutzer, der über organische Suche kam und dann auf einen intern UTM-getaggten Link klickt, erscheint in GA4 plötzlich als Besucher aus dem Kanal des UTM-Parameters.
UTM-Governance: Ohne Regeln wird es Chaos
Die Nutzung von UTM-Parametern allein reicht nicht. Ohne eine einheitliche, durchgesetzte Namenskonvention produziert das Team innerhalb weniger Monate einen Analytics-Datensalat. GA4 unterscheidet facebook, Facebook und FB als drei separate Quellen.
Kernelemente einer UTM-Governance:
- Namenskonvention: Nur Kleinschreibung, Unterstriche statt Leerzeichen, keine Sonderzeichen
- Standardisierte Werteliste: Eine feste, dokumentierte Liste erlaubter Werte für
utm_mediumund häufig verwendeteutm_source-Werte - Taxonomy Guardian: Eine namentlich benannte Person, die die Richtlinie pflegt, Schulungen durchführt und Datenqualität überwacht
- Zentrale Dokumentation: Alle erstellten UTM-Links in einem gemeinsam zugänglichen Dokument oder Tool erfassen
Die Links selbst erstellt man am schnellsten mit dem kostenlosen Campaign URL Builder von Google, der auch ohne GA4-Konto funktioniert.
Tabelle: Beispiel-UTM-Namenskonvention
| Regel / Parameter | Richtlinie | Beispiel |
|---|---|---|
| Allgemeine Regeln | Nur Kleinschreibung; Leerzeichen durch _ ersetzen; keine Sonderzeichen (?, &, =) in Werten |
winter_sale (nicht Winter Sale) |
| utm_medium | Feste Standardwerteliste, die mit GA4-Kanalgruppen übereinstimmt | cpc, paid_social, organic_social, email, referral, affiliate, display, offline_media |
| utm_source | Name der Plattform oder des spezifischen Ursprungsorts | google, bing, facebook, linkedin, newsletter_weekly, partner_xyz_blog |
| utm_campaign | Strukturiertes Format: [ziel]_[produkt/thema]_[jahr] |
leadgen_saas-tool_2025 oder sale_winter-jackets_2025 |
| utm_content | Differenzierung von Creatives oder Links innerhalb einer Kampagne | blue_banner_ad, header_link, video_ad_v1 |
| Verantwortlichkeit | Alle neuen Kampagnen vor Start beim Taxonomy Guardian zur Prüfung vorlegen | — |
| Tool | Alle UTM-Links über das zentrale Tool generieren und dokumentieren | — |
Technische Audits
Proaktive Kennzeichnung allein reicht nicht aus. Regelmäßige technische Überprüfungen identifizieren Tracking-Lücken, bevor sie die Daten dauerhaft verzerren.
Tracking-Code-Implementierung: Mithilfe des GTM Preview Mode, des GA4 DebugView oder Browser-Erweiterungen (empfehlenswert: Analytics Debugger) sicherstellen, dass der GA4-Tag auf jeder einzelnen Seite korrekt geladen wird.
Weiterleitungsketten: Tools wie Screaming Frog oder die Browser-Entwicklertools helfen dabei, lange Redirect-Ketten und JavaScript-Redirects zu identifizieren. Fehlerhafte Ketten korrigieren und UTM-Parameter-Übergabe sicherstellen.
HTTPS-Vollständigkeit: Audit aller internen Links auf HTTPS-Verwendung. Auch einzelne HTTP-Seiten können Referrer-Verlust verursachen.
Verweisausschlussliste in GA4: In den GA4-Einstellungen (Admin > Datenstreams > Web > Tag-Einstellungen konfigurieren > Unerwünschte Verweise auflisten) sicherstellen, dass die eigene Domain korrekt eingetragen ist, damit keine Self-Referrals entstehen. Gleichzeitig prüfen, dass keine legitimen externen Domains (z.B. Subdomains von Zahlungsanbietern) fälschlicherweise ausgeschlossen werden.
Direct Traffic als SEO-Signal: Mythos, Realität und indirekte Hebelwirkung
Ob Direct Traffic die Rankings beeinflusst, ist eine Frage, die in der SEO-Branche seit Jahren zu viel diskutiert wird. Die ehrliche Antwort ist: direkt nicht, indirekt aber erheblich.
Warum Direct Traffic kein direkter Rankingfaktor ist
Eine oft zitierte SEMrush-Korrelationsstudie aus dem Jahr 2017 stellte einen statistischen Zusammenhang zwischen hohem Direct Traffic und guten Rankings fest. Eine aktualisierte Variante aus dem Jahr 2024 zeigte eine Factor Strength von rund 12 Prozent für den Direct Traffic Share. Viele zogen daraus die Schlussfolgerung: Google wertet Direct Traffic als Rankingsignal.
Drei Einwände dagegen:
Erstens hat Google mehrfach erklärt, dass GA4-Daten nicht in den Algorithmus einfließen. Über den Chrome-Browser hätte Google zwar theoretisch Zugriff auf Traffic-Daten, aber deren Verwendung als direktes Rankingsignal wäre aus Datenschutz- und Qualitätsgründen fragwürdig.
Zweitens erklärt Korrelation keine Kausalität. Websites mit hoher Direct-Traffic-Rate sind typischerweise etablierte Marken mit starkem Content und guter Nutzererfahrung. Diese Eigenschaften sind der eigentliche Erfolgsfaktor. Dass solche Websites auch gut ranken, überrascht nicht; beide Effekte sind Folge derselben Ursache.
Drittens ist Direct Traffic als Metrik zu verrauscht, um als robustes Rankingsignal zu dienen. Wie die vorherigen Abschnitte zeigen, verbirgt sich dahinter ein Mix aus echten Zugriffen, fehlgeleiteten E-Mail-Klicks, App-Traffic und Tracking-Lücken. Ein Signal, das so leicht zu verfälschen und so schwer zu interpretieren ist, wäre für den Algorithmus wertlos.
Der Google-Leak 2024 und was er über Nutzersignale zeigt
Am 13. März 2024 veröffentlichte ein automatisierter Bot namens yoshi-code-bot interne Dokumente aus Googles Content API Warehouse auf GitHub, wo sie rund sechs Wochen öffentlich zugänglich waren. Die SEO-Experten Rand Fishkin (SparkToro) und Mike King (iPullRank) analysierten das Material und veröffentlichten ihre Erkenntnisse Ende Mai 2024. Die Echtheit der Dokumente wurde von mehreren ehemaligen Google-Mitarbeitern bestätigt; Google dementierte sie nicht, relativierte aber die Interpretation.
Was die Dokumente zeigen, ist für die Diskussion um Nutzersignale und Direct Traffic relevant: Das System NavBoost existiert, ist seit mindestens 2005 aktiv und verwendet klickbasierte Metriken, um Suchergebnisse nachträglich zu justieren. Die Dokumentation listet explizit Metriken wie goodClicks, badClicks und lastLongestClicks. Langklicks, also Besuche mit langer Verweildauer ohne Rückkehr zur SERP, gelten demnach als positives Signal; schnelle Rücksprünge (Pogo-Sticking) können Abwertungen auslösen. NavBoost wertet dabei historische Klickdaten aus einem Zeitraum von rund 13 Monaten aus und berücksichtigt geografische und gerätespezifische Unterschiede.
Dass Google Chrome-Daten in irgendeiner Form nutzt, bestätigte im Rahmen des DOJ-Kartellverfahrens gegen Google sogar Pandu Nayak, Vizepräsident der Google-Suche. Google-Sprecher Gary Illyes hatte hingegen noch 2023 öffentlich erklärt, Chrome-Daten seien für Rankings zu ungenau. Das Leak hat diese Aussage in ein anderes Licht gerückt.
Wichtige Einschränkungen: Die Dokumente zeigen, welche Felder und Signale im System vorhanden sind, nicht wie sie gewichtet werden. Die Dokumente enthalten Verweise auf eingestellte Dienste wie Google+, was auf einen älteren Dokumentenkorpus hindeutet. Und sie zeigen nichts über SGE/AI Overviews, Personalisierungsalgorithmen oder aktuelle Gewichtungsparameter.
Für die Bewertung von Direct Traffic ändert das Leak im Kern nichts, es schärft aber das Bild:
Google misst nicht einfach „Traffic", sondern qualitative Interaktionssignale im Kontext von Suchanfragen. Ein Nutzer, der direkt auf eine Seite kommt und sich intensiv damit beschäftigt, sendet ein anderes Signal als einer, der nach drei Sekunden abspringt. Direct Traffic selbst ist kein Rankingsignal, das engagierte Verhalten dahinter schon eher.
Die indirekte Wirkung
Der eigentliche SEO-Wert liegt woanders.
Brand Signals: Wenn Nutzer die Suchmaschine bewusst umgehen, um eine Seite direkt anzusteuern, zeigt das ein hohes Maß an Vertrauen und Bekanntheit. Google versucht, solche autoritativen Marken zu erkennen und zu bevorzugen.
Nutzersignale: Direkte Besucher wissen, was sie erwartet. Die Engagement-Rate ist höher, die Verweildauer länger, die Absprungrate niedriger. Ob und in welchem Umfang Google solche Signale über Chrome oder aggregierte Daten auswertet, bleibt teilweise unklar. Dass sie eine Rolle spielen, gilt unter erfahrenen SEOs als konsensual, auch wenn offizielle Bestätigungen spärlich sind.
E-E-A-T: Eine loyale, direkt zugreifende Nutzerschaft ist das stärkste Argument für Vertrauen und Autorität. Wer so bekannt ist, dass Nutzer nicht mehr suchen müssen, hat Topical Authority aufgebaut, die sich in Backlinks, Brand Mentions und organischer Sichtbarkeit niederschlägt.
Aus dieser Perspektive gilt: Die beste SEO-Strategie ist nicht allein Keyword-Optimierung, sondern der Aufbau einer Marke, die so stark ist, dass Nutzer die Suche für überflüssig halten.
Strategien zur Steigerung von echtem Direct Traffic
Diese Maßnahmen sind keine kurzfristigen Hebel. Sie sind Investitionen in Markenbekanntheit und Nutzerbindung, die mittelfristig auch die organische Sichtbarkeit stärken.
Markenbekanntheit aufbauen
Wer erinnert wird, wird direkt besucht. Das beginnt mit einem kurzen, leicht zu merkenden Domainnamen. Es setzt sich fort mit konsistenter visueller Präsenz über alle Kanäle: Website, Social Media, E-Mail-Signatur, Präsentationen, Visitenkarten.
Offline-Maßnahmen sind unterschätzt. Jede Print-, Radio-, TV- oder Event-Präsenz ist eine Chance, den Markennamen so zu verankern, dass er als nächstes in die Browserleiste getippt wird.
Emotionale Verbindungen helfen: Marken, die eine Geschichte erzählen und nicht nur Produkte beschreiben, bleiben länger im Gedächtnis. Das ist kein Marketing-Bullshit, sondern Neuropsychologie.
User Experience als Loyalitätsfaktor
Wiederkehrende Besuche entstehen, wenn ein Besuch sich gelohnt hat.
Seitenladezeit unter drei Sekunden auf dem Smartphone ist keine Empfehlung mehr, sondern Mindeststandard. Wer Mobile-Performance vernachlässigt, verliert einen Großteil der wiederkehrenden Besucher, bevor sie überhaupt gelesen haben.
Eine klare Navigationsstruktur reduziert Frustration. Nutzer, die schnell finden, was sie suchen, kommen wieder. Nutzer, die sich durch inkonsistente Menüs kämpfen, kommen nicht.
Content, der Lesezeichen verdient
Standardblogartikel setzen keine Lesezeichen. Inhalte mit außergewöhnlichem Wert schon.
Was das konkret bedeutet: Umfassende Leitfäden, die regelmäßig aktualisiert werden; interaktive Tools oder Rechner; proprietäre Daten oder Branchen-Benchmarks; detaillierte Schritt-für-Schritt-Anleitungen, die nicht nur Theorie beschreiben.
Themenautorität und das Pillar-Cluster-Modell
Wer zu einem Themenfeld konsequent die fundiertesten Inhalte liefert, wird zur Anlaufstelle. Das Pillar-Cluster-Modell strukturiert das systematisch: eine übergeordnete Pillar-Page pro Kernthema, ergänzt durch Cluster-Artikel zu Teilaspekten und Long-Tail-Keywords, alle durch interne Links verbunden.
Aus SEO-Sicht stärkt das die interne Verlinkung und semantische Relevanz. Aus Nutzersicht entsteht ein kohärentes Informationsangebot statt loser Einzelartikel.
Wenn jemand wiederholt erlebt, dass eine Website zu einem Thema die zuverlässigsten Antworten liefert, entsteht Vertrauen, das sich in direkten Zugriffen und niedrigeren Bounce-Rates niederschlägt. Und ja, das ist auch der indirekte SEO-Effekt.
Aufbau von Themenautorität
durch das Pillar-Cluster-Modell
Keywords
erweiterung
aspekte
Kernthema-Hub
Fragen
Inhalte
beispiele
SEO-Wirkung
Stärkung der internen Verlinkung, besseres Verständnis thematischer Zusammenhänge für Suchmaschinen und erhöhte semantische Relevanz.
Nutzererfahrung
Konsistentes Informationsangebot, das ein Thema ganzheitlich und strukturiert erschließt – nicht nur einzelne Fragen beantwortet.
Vertrauensaufbau
Fundierte, aktuelle Inhalte erzeugen Vertrauen und direkte Rückkehr – statt erneuter Google-Suche beim nächsten Bedarf.
Starke Themenautorität führt zu messbaren SEO-Verbesserungen durch positive Nutzersignale
Newsletter und Community
Ein regelmäßiger, wertvoller Newsletter hält die Marke im Bewusstsein der Abonnenten. Er liefert Anlass für wiederkehrende Besuche. Er ist einer der wenigen Kanäle, der nicht von Algorithmen abhängig ist.
Eine Community rund um die eigenen Inhalte oder Produkte zu schaffen, etwa über ein Forum oder eine geschlossene Gruppe, verstärkt den Effekt. Nutzer, die sich einer Community zugehörig fühlen, besuchen die zugehörige Website deutlich häufiger und direkter.
Zusammenfassung: Was Direct Traffic wirklich aussagt
Ein paar Kernpunkte, die es wert sind, im Kopf zu bleiben:
Direct Traffic ist gleichzeitig ein wertvoller Indikator für Markenstärke und ein Symptom für Tracking-Schwächen. Beides kann gleichzeitig zutreffen. Eine undifferenzierte Betrachtung führt zu falschen Schlüssen in beide Richtungen.
Die wichtigste analytische Fähigkeit ist die Unterscheidung zwischen echtem Direct Traffic und Dark Traffic. Landingpage-Analyse, Geräteaufteilung und zeitliche Korrelation mit Kampagnenaktivitäten sind die praktischen Werkzeuge dafür.
Datenhygiene ist kein einmaliges Projekt. Eine strenge UTM-Governance und regelmäßige technische Audits sind keine IT-Aufgaben, sondern Marketing-Grundlagen.
Der SEO-Einfluss ist indirekt, aber real. Wer echten Direct Traffic aufbaut, baut Markenstärke auf. Markenstärke führt zu besseren Nutzersignalen. Bessere Nutzersignale unterstützen organische Sichtbarkeit. Diese Kausalitätskette ist nicht spektakulär, aber sie hält.
Ausblick: Die Attribution wird in den nächsten Jahren strukturell schwieriger, nicht einfacher. Third-Party-Cookies sind praktisch Geschichte. Datenschutzbeschränkungen verschärfen sich. AI-Suchsysteme werden zu einer weiteren Blackbox für Referrer-Daten. Wer jetzt in saubere First-Party-Daten, UTM-Governance und gegebenenfalls Server-Side Tagging investiert, hat in zwei Jahren einen messbaren Informationsvorteil gegenüber denen, die noch auf den alten Passivsystemen sitzen. Und wer sich auf echten Markenaufbau konzentriert, statt auf Attribution-Akrobatik, hat die robusteste Antwort auf eine zunehmend undurchsichtige Tracking-Welt.
FAQ: Direct Traffic in GA4
Was ist Direct Traffic in GA4 und wie entsteht er?
Direct Traffic ((direct) / (none)) bezeichnet Besuche, bei denen GA4 keine Herkunftsinformationen empfangen hat. Das kann echte direkte Zugriffe durch manuelle URL-Eingabe oder Lesezeichen bedeuten, aber auch Traffic aus WhatsApp-Links, Desktop-E-Mail-Clients, PDFs, App-internen Browsern und fehlkonfigurierten Kampagnen.
Was ist Dark Traffic und woher kommt er?
Dark Traffic ist der Teil des Direct Traffics, der eigentlich aus anderen Kanälen stammt, aber seinen Referrer unterwegs verloren hat. Hauptquellen sind private Messaging-Dienste (Dark Social), mobile App-Browser, Links in Offline-Dokumenten und fehlerhafte Weiterleitungen.
Wie hoch darf der Direct-Traffic-Anteil realistischerweise sein?
Für die meisten Websites gilt ein Anteil von 5 bis 20 Prozent als normal. Alles über 20 bis 25 Prozent sollte untersucht werden, insbesondere wenn gleichzeitig ein anderer Kanal einbricht.
Wie reduziere ich fehlerhaft zugewiesenen Direct Traffic?
Die wichtigsten Maßnahmen: konsequente UTM-Parameter für alle externen Marketing-Links, unternehmensweite UTM-Namenskonvention, vollständige HTTPS-Migration, technische Audits der GA4-Implementierung und Audit aller Weiterleitungsketten.
Hat Direct Traffic direkten Einfluss auf Google-Rankings?
Nein, nicht direkt. GA4-Daten fließen nach Googles Aussage nicht in den Algorithmus ein, und Direct Traffic als Metrik ist zu ungenau, um als robustes Rankingsignal zu dienen. Die indirekte Wirkung über Brand Signals und Nutzersignale ist dagegen real.
Was ist der Unterschied zwischen Direct Traffic und Unassigned Traffic in GA4?
Direct Traffic entsteht durch fehlende Herkunftsdaten (kein Referrer, keine UTMs). Unassigned Traffic ist ein Klassifizierungsfehler: GA4 hat eine Quelle, kann sie aber keiner vordefinierten Kanalgruppe zuordnen, meistens wegen falschem UTM-Tagging.
Warum erscheint E-Mail-Traffic manchmal als Direct Traffic?
Desktop-E-Mail-Clients wie Outlook senden keinen HTTP-Referrer. Wenn Links in E-Mails keine UTM-Parameter tragen, kann GA4 den Ursprung nicht ermitteln und klassifiziert den Besuch als Direct.
Wie beeinflusst Apple ITP den Direct-Traffic-Anteil?
ITP begrenzt die Lebensdauer clientseitig gesetzter Cookies auf 7 Tage (in manchen Fällen 24 Stunden) und entfernt Tracking-Parameter aus URLs. Das unterbricht Attributionsketten, die länger als diese Zeiträume andauern, und erhöht den scheinbaren Anteil direkter Zugriffe.


Kommentare