Logfile-Analyse: Was dein Access Log zeigt, was GSC und Analytics dir nicht zeigen
Dein Webserver protokolliert jeden Crawl-Zugriff, ungefiltert und in Echtzeit. Wer weiß, wie man liest, findet damit technische Probleme, Crawling-Muster und AI-Crawler, die in keinem anderen Tool auftauchen.
tl;dr: Ein Access Log protokolliert jeden einzelnen Crawl-Zugriff auf deinen Webserver, egal ob von Googlebot, Bingbot oder einem der mittlerweile zahlreichen AI-Crawler. Google Analytics zeigt dir das nicht, die Search Console auch nicht. Wer die Rohdaten lesen kann, findet damit Crawling-Probleme, Budget-Verschwendung und technische Fehler, die mit jedem anderen Tool unsichtbar blieben. Und seit 2023 sieht man dort auch, welche AI-Systeme deine Inhalte crawlen.
Was ist ein Access Log?
Ein Logfile, genauer ein Access Log, ist eine Textdatei, die dein Webserver automatisch fortschreibt. Jeder Zugriff auf eine URL hinterlässt eine Zeile, egal ob ein menschlicher Besucher dahintersteckt oder ein Bot.
Ein typischer Eintrag sieht so aus:
000.000.000.000 - - [11/Jul/2017:08:04:41 +0200] "GET /logo.jpg HTTP/1.0" 200 285 "https://www.beispiel.de/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"Diese Zeile enthält:
IP-Adresse des anfragenden Clients (Besucher oder Bot)
Zeitstempel des Zugriffs
Angeforderte URL (HTTP-Methode, Pfad, Protokoll)
HTTP-Statuscode (200 = OK, 301 = Redirect, 404 = nicht gefunden, 500 = Serverfehler)
Übertragene Datenmenge in Byte
Referrer-URL, von der der Zugriff kam, sofern bekannt
User-Agent-String: Browser, Bot oder Crawler-Kennung
Wichtig vorab: Das Access Log ist nicht dasselbe wie das Error Log. Error Logs protokollieren ausschließlich Server-Fehler. Das Access Log protokolliert alles, auch erfolgreiche Requests, und genau das macht es für SEO zur primären Diagnosequelle.

Was das Access Log sichtbar macht, was andere Tools verbergen
Google Analytics zeigt dir Nutzerverhalten. Die Search Console zeigt dir Klicks, Impressionen und Googles Indexierungsstatus. Beides sind gefilterte, aggregierte oder verzögerte Daten, aufbereitet nach Googles Kriterien und mit Googles blinden Flecken.
Das Access Log arbeitet anders. Es protokolliert jede einzelne Serveranfrage in Echtzeit, unabhängig davon, ob Google sie dir anzeigen will oder nicht. Das macht es zur einzigen Quelle, die dir verlässlich zeigt:
Welche Seiten werden wie oft von Googlebot gecrawlt? Werden wichtige Inhalte priorisiert, oder landet der Bot hauptsächlich auf URLs ohne SEO-Wert?
Welche AI-Crawler besuchen deine Website? GPTBot, ClaudeBot, PerplexityBot und Co. tauchen weder in GA4 noch in der Search Console auf. Nur im Access Log.
Crawling-Probleme: Gibt es Seiten, die gar nicht oder nur selten gecrawlt werden, obwohl sie relevant sind?
Crawl-Budget-Verschwendung: Werden Crawler-Ressourcen auf URLs ohne SEO-Wert verbraucht?
Technische Fehler: 404-Fehler, Redirect-Ketten, Serverfehler, die das Crawling behindern.
Bot-Verifikation: Meldet sich ein Bot als Googlebot, ist aber keiner? Das Access Log liefert die Rohdaten für den Reverse-DNS-Lookup.
Bei kleinen Websites ist das oft vernachlässigbar. Bei größeren Projekten mit regelmäßigen Relaunches, technischen Schulden oder vielen URL-Varianten ist das Access Log häufig die schnellste Diagnoseroute.
Herausforderungen in der Praxis
Datenmenge. Auf aktiven Servern wachsen Access Logs schnell auf mehrere Gigabyte. Du brauchst ein Tool, das damit umgehen kann, oder filterst die Logs vorher auf dem Server auf den relevanten Zeitraum.
Technisches Know-how. Die Rohdaten zu lesen ist einfach. Die Muster zu interpretieren und die richtigen Schlüsse zu ziehen, das erfordert Erfahrung im technischen SEO.
Zugriff. Nicht jeder Hoster gibt dir unkomplizierten Zugriff auf Roh-Logfiles. Wer dir nur aufbereitete Statistiken liefert, nicht die echten Access Logs, schränkt deine Analysemöglichkeiten erheblich ein. Wie gut dein Hoster hier mitspielt, ist ein aussagekräftiges Signal für die technische Souveränität des Hosting-Pakets. Für SEO-intensive Projekte ist Logfile-Zugriff ein Auswahlkriterium.
Datenschutz. IP-Adressen gelten in der EU als personenbezogene Daten. Wenn du Logs an externe Dienste übermittelst, müssen sie vorher anonymisiert sein. Das gilt ohne Ausnahme für alle Cloud-basierten Analyse-Tools, also auch für Semrush und vergleichbare Dienste.
Fragmentierte Logs. Wer ein CDN einsetzt, hat Logdaten auf mehreren Ebenen: Ursprungsserver und CDN-Knoten loggen getrennt. Für eine vollständige Analyse müssen diese Quellen zusammengeführt werden. Das erhöht den Aufwand erheblich und birgt Risiken für Datenlücken, wenn die Quellen nicht korrekt synchronisiert werden.
Tools für die Logfile-Analyse
Wer programmieren kann oder entsprechende Ressourcen einkauft, ist hier wie in vielen anderen Bereichen der SEO klar im Vorteil. Alle fertigen Tools zwingen dir einen bestimmten Workflow auf und bieten festgelegte Reports, die sich nicht unbedingt anpassen lassen. Eine Lösung, die genau auf deine Anforderungen zugeschnitten ist, wird immer relevantere Ergebnisse liefern.
Vorbereitung
Drei Schritte, bevor du mit der eigentlichen Analyse anfängst:
Datenzugriff klären. Kläre mit deinem Hoster, wie du regelmäßig und zuverlässig an die Roh-Logs kommst. Automatisierter Zugriff ist besser als manuelle Downloads alle paar Wochen.
Datenbereinigung. Filtere interne IPs heraus, wenn du oder dein Team regelmäßig die eigene Website aufruft. Bekannte Spam-Bots und Monitoring-Dienste sollten ebenfalls entfernt werden, damit sie Crawl-Frequenz-Auswertungen nicht verfälschen.
Bot-Verifizierung. Wer behauptet, Googlebot zu sein, ist nicht automatisch Googlebot. Ein Reverse-DNS-Lookup gegen Googles dokumentierte IP-Ranges ist der zuverlässige Weg zur Verifikation.
Screaming Frog Log File Analyser
Benutzerfreundlich, direkt auf SEO-Zwecke ausgerichtet, gute Visualisierungen. Du kannst Crawl-Daten aus dem Screaming Frog SEO Spider oder anderen Tools importieren und mit den Logdaten kombinieren, zum Beispiel um Orphan Pages zu identifizieren: URLs, die im Log auftauchen, aber nirgends intern verlinkt sind. Kostenpflichtig. Stößt bei sehr großen Log-Volumes an seine Grenzen.

ELK Stack (Elasticsearch, Logstash, Kibana)
Open-Source, hochskalierbar, Echtzeit-Analyse möglich. Geeignet für sehr große Websites mit komplexen Anforderungen. Einrichtung und Konfiguration erfordern technisches Know-how, das ist kein Tool für den schnellen Einstieg.
Google BigQuery
Verarbeitet große Datenmengen, eng mit anderen Google-Tools integriert, SQL-basiert. Bei größeren Datenmengen kostspielig. SQL-Kenntnisse sind Voraussetzung, um die Daten effektiv abfragen zu können.
Python oder R mit spezialisierten Bibliotheken
Die flexibelste Option, kostenlos, aber nichts für Anfänger. Die Möglichkeiten sind faktisch grenzenlos: Du schreibst genau die Auswertung, die du brauchst, und kannst sie automatisiert laufen lassen.
HTTP Logs Viewer (früher Apache Logs Viewer)
Solides, einfach zu bedienendes Tool für erste Überblicke. Wird selten aktualisiert, bietet überwiegend festgelegte Reports, optisch altbacken.
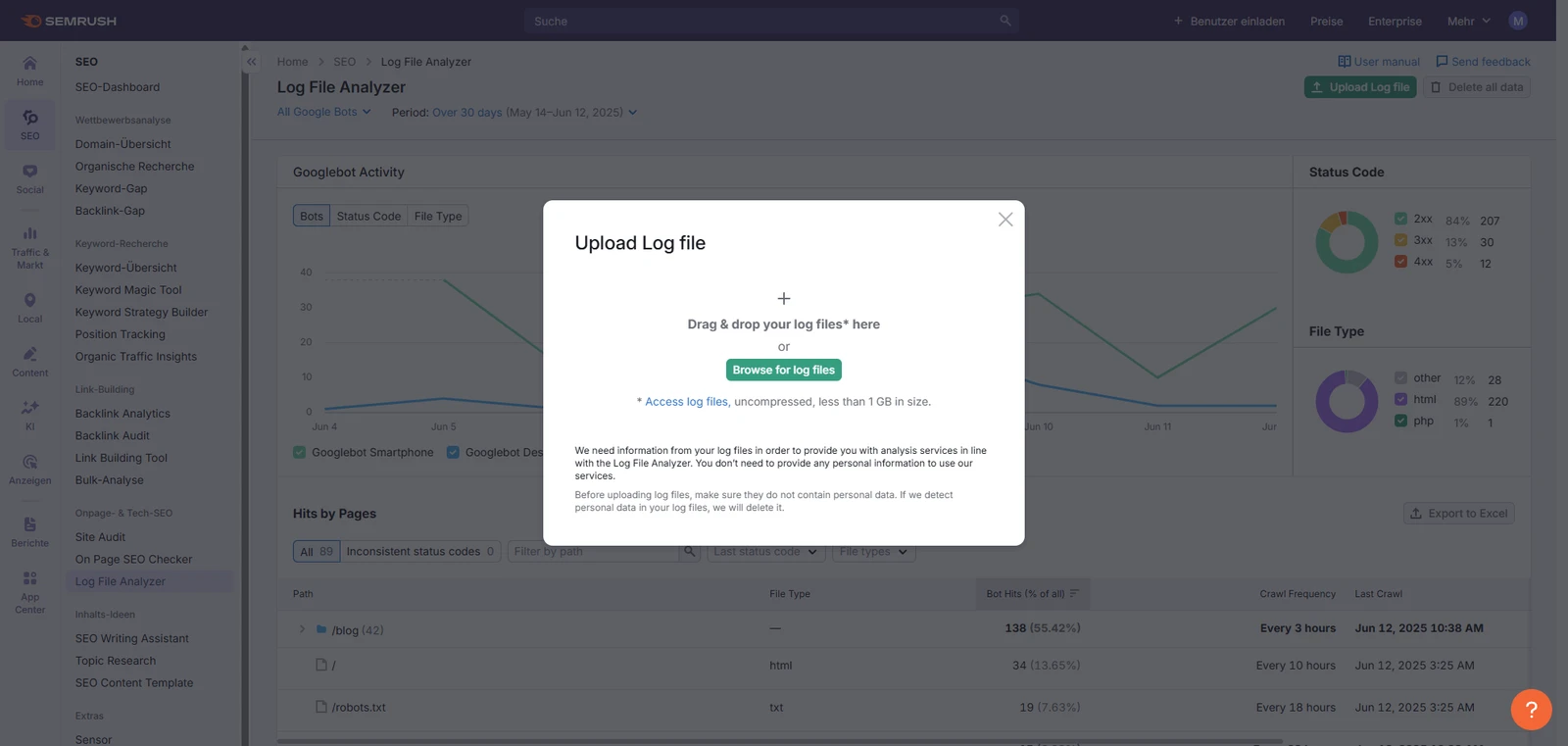
Semrush Log File Analyzer
Für Semrush-Nutzer ohne Extrakosten dabei. Verarbeitet Logfiles bis 1 GB. Zeigt sofort und übersichtlich Statuscode, Crawl-Frequenz und letzten Zugriff. Einfacher Export nach Excel. Einschränkung: Berücksichtigt ausschließlich Googlebot Smartphone und Googlebot Desktop, keine anderen Crawler. IP-Adressen solltest du vor dem Upload anonymisieren.
AI-Crawler im Log: Die zweite Dimension
Seit 2023 hat sich die Zusammensetzung der Crawler in typischen Access Logs verändert. Neben Googlebot, Bingbot und Yandex tauchen jetzt regelmäßig User-Agents auf, die du vor drei Jahren noch nicht kanntest: GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity AI), Google-Extended (Googles AI-Training-Datensammlung), Amazonbot, Meta-ExternalAgent und weitere.
Das ist der Punkt, an dem die klassische Logfile-Analyse eine neue Dimension bekommt.
GA4 trackt keine Bots. Die Search Console zeigt dir ausschließlich Googlebot-Aktivität. Was die anderen AI-Crawler auf deiner Website treiben, siehst du ausschließlich im Access Log. Das ist keine Randnotiz, sondern eine der wenigen direkt messbaren Eingangsvariablen in einem ansonsten weitgehend intransparenten System.
Zwei Arten von AI-Crawlern
AI-Systeme greifen auf Webinhalte über zwei grundsätzlich unterschiedliche Wege zu:
Trainingscrawler (z.B. GPTBot, ClaudeBot, Google-Extended) lesen Inhalte für das Modell-Training. Sie haben keinen direkten Zusammenhang mit einer konkreten Nutzeranfrage, aber sie bestimmen, was ein Modell grundsätzlich über deine Website und deine Themen "weiß".
Retrieval-Crawler (z.B. ChatGPT-User, PerplexityBot bei aktiven Suchen) crawlen in Echtzeit, wenn ein Nutzer gerade eine Anfrage stellt. Diese Besuche haben eine direktere Verbindung zu möglichen Zitierungen in AI-Antworten.
Die Unterscheidung ist für deine robots.txt-Entscheidungen relevant: Wer einen Bot blockiert, blockiert in der Regel beide Zugriffsmodi des jeweiligen Anbieters.
Was du im Log konkret siehst
Du siehst nicht nur, welche User-Agents aufgetaucht sind, sondern auch welche URLs gecrawlt wurden, wann, wie häufig, mit welchem Statuscode, und ob bestimmte Bereiche komplett ignoriert werden. Das liefert die Datenbasis für konkrete Entscheidungen:
Welche AI-Systeme crawlen meine Website überhaupt?
Crawlen sie Seiten, die ich für AI-Systeme freigeben will?
Gibt es Bots, die sich als bekannte AI-Crawler ausgeben, aber nicht verifiziert werden können?
Crawlt ein System intensiv, obwohl ich in den entsprechenden AI-Antworten nicht auftauche?
Wer AI-Crawler pauschal blockiert oder ohne Datenbasis selektiv zulässt, handelt ins Blaue. Das Access Log zeigt dir die Realität.
Für diese Auswertung habe ich einen Browser-basierten Analyzer gebaut: AI Bot Logfile Analyzer. Er erkennt aktuell 14 AI-Crawler anhand ihrer User-Agent-Strings, verarbeitet die Logs vollständig lokal im Browser ohne Datenübertragung, und exportiert die Ergebnisse als CSV. Das löst auch das Datenschutzproblem: keine Übertragung an Drittserver, keine Anonymisierungspflicht vor dem Upload.
Einen tieferen Blick auf die strategische Seite, also wer welchen Bot zulassen sollte und was diese Entscheidung für AI-Sichtbarkeit bedeutet, findest du hier: AI Crawler Strategie: Wer sie wirklich braucht, was sie bringt.
Kernmethoden der SEO-Logfile-Analyse
Crawl-Frequenz-Analyse
Welche Seiten crawlt Googlebot, und wie oft? Das ist die grundlegendste Auswertung und oft schon die aufschlussreichste. Seiten, die kaum gecrawlt werden, werden in der Regel auch seltener mit frischen Inhalten im Index aktualisiert. Seiten, die unverhältnismäßig oft gecrawlt werden, obwohl sie keinen SEO-Wert haben, verbrauchen Crawl-Kapazität, die an anderer Stelle fehlt.
Crawl-Frequenz nach Seitentyp auswerten: Werden Produktseiten, Kategorieseiten und Blogbeiträge mit der erwarteten Häufigkeit gecrawlt? Wenn bestimmte Seitentypen systematisch unterrepräsentiert sind, ist das ein Hinweis auf interne Verlinkungsprobleme oder eine Seitenarchitektur, die Crawler von diesen URLs fernhält.
Zeitliche Muster sind ebenfalls interessant: Wann crawlt Googlebot besonders intensiv? Das hilft bei der Serverplanung für Websites, bei denen Crawl-Aktivität und Nutzerlast zusammentreffen.
Crawl-Tiefe
Wie tief dringt Googlebot in deine Seitenstruktur ein? Seiten, die nur über mehrere Klickebenen erreichbar sind, werden weniger häufig gecrawlt. Wenn wichtige Inhalte tief in der Struktur liegen und selten gecrawlt werden, ist das ein Indikator für Probleme in der internen Verlinkung.
Statuscode-Auswertung
404-Fehler, 500-Fehler, Redirect-Ketten: Das Access Log zeigt dir alle HTTP-Antwortcodes in vollständiger Rohform. Im Screaming Frog Log File Analyser oder einem vergleichbaren Tool lassen sich diese schnell aggregieren und nach Häufigkeit sortieren.
Eine gesunde Statuscode-Verteilung hat 200er-Antworten als klaren Hauptanteil, wenige 301-Redirects, und Fehler-Codes nahe null.
Crawl-Budget
Das Crawl-Budget ist die Crawl-Kapazität, die Google einer Website innerhalb eines bestimmten Zeitraums zuweist. Dieser Faktor wird erst ab einer bestimmten Größenordnung zum echten Engpass, in der Praxis grob ab 10.000 Seiten. Sehr große Websites mit 100.000+ URLs oder Projekte mit sehr häufigen Content-Updates sind die typischen Kandidaten für eine aktive Crawl-Budget-Optimierung.
Für kleinere Websites ist die Crawl-Budget-Frage meistens kein Problem, weil Googlebot alle relevanten Seiten ohnehin crawlt. Trotzdem kann es sinnvoll sein, URLs ohne SEO-Wert vom Crawling auszuschließen: Session-IDs, Filterkombinationen, Test-URLs, alte Staging-Pfade, Druckerversionen. Das räumt auf und verhindert, dass Crawler Zeit auf Seiten verbringen, die nie indexiert werden sollten.
Technische SEO-Probleme erkennen und beheben
Hier zeigt das Access Log Probleme, die in der Search Console oft erst mit Verzögerung sichtbar werden oder gar nicht auftauchen.
Orphan Pages
Seiten, die nirgends intern verlinkt sind, aber dennoch gecrawlt werden. Das können alte Seiten sein, die nie entfernt wurden, fehlerhafte Redirects oder URLs, die Suchmaschinen über externe Links oder alte Sitemaps kennen. Die Kombination aus Log-Daten und Crawl-Daten im Screaming Frog macht diese besonders greifbar: Du siehst, welche URLs im Log auftauchen, aber in keinem Menü und keinem internen Link verlinkt sind.
Duplicate Content über URL-Variationen
Wenn dieselbe Seite unter verschiedenen URLs gecrawlt wird, zum Beispiel mit und ohne abschließenden Schrägstrich, mit und ohne "www", oder mit unterschiedlichen URL-Parametern, hat Googlebot potenziell ein Duplicate-Content-Problem.
Das Log zeigt dir, ob trotz gesetzter Canonical-Tags mehrere Varianten gecrawlt werden. Wenn ja, stimmt mit der Canonical-Implementierung etwas nicht. Parameterbasierten Duplicate Content, also Tracking-Parameter oder Sortier-Optionen, die als separate URLs gecrawlt werden, kannst du über die Search Console konfigurieren oder über Canonical-Tags bereinigen.
Redirect-Ketten und Redirect-Loops
Lange Weiterleitungsketten, bei denen URL A auf B weiterleitet, die wiederum auf C verweist, verlangsamen das Crawling und können dazu führen, dass Googlebot die Ziel-URL gar nicht mehr erreicht. Redirect-Loops verhindern das Indexieren vollständig. Das Access Log macht beides sichtbar.
Serverantwortzeiten
Standard-Access-Logs enthalten keine serverseitigen Ladezeiten. Wenn dein Server oder dein Hoster erweiterte Logs konfiguriert, sieht ein Eintrag mit Response-Time so aus:
192.168.1.100 - - [13/Jun/2025:10:30:45 +0200] "GET /products/laptop.html HTTP/1.1" 200 15234 "https://example.com/search" "Mozilla/5.0..." 0.245Der letzte Wert (0.245) ist die Server-Response-Time in Sekunden. Wenn bestimmte URL-Typen regelmäßig hohe Response-Times aufweisen, ist das ein Hinweis auf Datenbankabfragen, ungecachte Seiten oder andere serverseitige Probleme.
Sicherheitsrelevante Muster
Logfiles zeigen auch ungewöhnliche Zugriffsmuster: plötzliche Request-Spikes auf Admin-Pfade, SQL-Injection-Versuche in URL-Parametern, Bots, die sich als Googlebot ausgeben, aber beim Reverse-DNS-Lookup nicht verifiziert werden können. Das ist für SEO insofern relevant, als kompromittierte Websites von Google mit Warnhinweisen belegt oder aus dem Index entfernt werden.
Mobile-First-Indexierung: Was das Log seit Juli 2024 zeigt
Seit dem 5. Juli 2024 hat Google den letzten Schritt der Mobile-First-Migration umgesetzt: Auch die wenigen bis dahin verbliebenen Websites, die noch mit dem Googlebot Desktop für die Websuche verarbeitet wurden, werden seitdem mit dem Googlebot Smartphone gecrawlt. Für Indexierung und Ranking ist der mobile Crawler damit der primäre Crawler für alle Websites.
Das bedeutet nicht, dass Googlebot Desktop aus deinen Logs verschwindet. Google dokumentiert weiterhin beide Crawler-Typen und beschreibt, dass ein kleiner Teil der Requests weiterhin Desktop-basiert sein kann. Was sich geändert hat: Es gibt keine Websites mehr, die primär mit dem Desktop-Crawler für die Websuche indexiert werden.
Für deine Log-Auswertung bedeutet das eine Verschiebung der relevanten Fragen:
Das Verhältnis Googlebot Smartphone zu Googlebot Desktop ist kein zuverlässiger Diagnosewert mehr für den Mobile-First-Status. Interessant sind jetzt folgende Fragen:
Crawlt Googlebot Smartphone alle wichtigen Seiten mit der erwarteten Frequenz?
Kann der mobile Crawler auf alle Ressourcen zugreifen, die er für das korrekte Rendering braucht: CSS, JavaScript, Bilder?
Gibt es Seiten, die für Desktop-Nutzer erreichbar sind, aber für mobile Crawler Fehler zurückgeben?
Stimmt die Crawl-Tiefe für den mobilen Crawler mit dem überein, was du dir für diese Seiten vorstellst?
Wichtig: Google indexiert auch Seiten, die nicht mobilfreundlich gestaltet sind, solange sie auf Mobilgeräten grundsätzlich erreichbar sind. Seiten, die auf Mobilgeräten gar nicht laden, sind hingegen nicht indexierbar.
Internationale und mehrsprachige Websites
Für Websites, die mehrere Länder und Sprachen bedienen, kommen einige spezifische Herausforderungen dazu.
Sprachversionen gleichmäßig gecrawlt? Das Log zeigt, ob bestimmte Sprachversionen deutlich seltener gecrawlt werden als andere. Das kann auf Probleme in der internen Verlinkung zwischen Sprachversionen hinweisen oder darauf, dass eine Sprachversion schwer erreichbar ist.
hreflang-Implementierung prüfen. Wenn hreflang-verlinkte Seiten gar nicht gecrawlt werden, ist die Implementierung fehlerhaft. Suchmaschinen sollen die Beziehungen zwischen Sprachversionen über hreflang verstehen, aber das setzt voraus, dass alle verlinkten URLs tatsächlich gecrawlt werden. Das Log zeigt dir, ob das der Fall ist.
Duplicate-Content-Risiko bei gleicher Sprache. Deutschland und Österreich sprechen beide Deutsch. Wenn beide Versionen nahezu identischen Content haben, ist Canonicalization relevant. Das Log zeigt, ob Googlebot beide Versionen separat crawlt und ob Canonical-Tags korrekt greifen.
IP-basierte Geo-Redirects sind eine Falle. Wenn Besucher aus einem bestimmten Land automatisch auf eine andere URL weitergeleitet werden, sieht Googlebot eine andere URL als ein Nutzer, der manuell navigiert. Das kann zu inkonsistenten Bot-Weiterleitungen führen, die das Log sichtbar macht. Von IP-basierten Redirects rate ich grundsätzlich ab.
Logfile-Analyse in den SEO-Workflow integrieren
Logfile-Analyse ist kein einmaliger Diagnose-Sprint. Sie wird als Datenquelle stärker, wenn sie regelmäßig läuft und mit anderen Quellen kombiniert wird.
Erkenntnisse aus den Logs werden aussagekräftiger, wenn du sie gegen den Indexierungsstatus aus der Search Console hältst und gegen Performance-Metriken aus GA4. Seiten, die Googlebot regelmäßig crawlt, aber in der Search Console als "entdeckt, aber nicht indexiert" auftauchen, sind ein typisches Diagnosemuster, das nur durch die Kombination beider Quellen sichtbar wird.
Automatisierte Berichte, die regelmäßig auf 4xx- und 5xx-Fehler hinweisen oder auf Veränderungen in der Crawl-Frequenz reagieren, machen den Unterschied zwischen reaktiver Fehlerbehebung und proaktivem technischen SEO.
Ohne solide technische Grundlage verpuffen alle weiteren Optimierungen an Content oder Usability. Das gilt für klassisches SEO genauso wie für AI Search Optimization. Das Access Log ist ein wesentlicher Teil dieser Grundlage, und es ist der Teil, den die wenigsten regelmäßig anschauen.
FAQ
-
Was ist ein Access Log und wofür wird es in der SEO genutzt?
Ein Access Log ist eine Textdatei, die dein Webserver automatisch fortschreibt. Jeder Zugriff auf eine URL hinterlässt eine Zeile, unabhängig davon, ob ein menschlicher Besucher oder ein Bot dahintersteckt. Für SEO ist das Access Log die einzige Datenquelle, die das vollständige Crawling-Verhalten von Suchmaschinen in Echtzeit zeigt, ohne Aggregation und ohne den Interpretations-Filter von Google Analytics oder der Search Console.
-
Was ist der Unterschied zwischen Access Log und Error Log?
Das Access Log protokolliert alle HTTP-Anfragen an den Server, einschließlich erfolgreicher Requests und Crawler-Aktivitäten. Das Error Log protokolliert ausschließlich Server-Fehler, Warnungen und Probleme. Für die SEO-Analyse ist das Access Log die primär relevante Quelle, da es das vollständige Crawling-Verhalten zeigt.
-
Ab welcher Websitegröße ist Crawl-Budget-Optimierung relevant?
Das Crawl-Budget wird typischerweise erst bei Websites mit grob 10.000 Seiten aufwärts zum echten Engpass, da Google bei kleineren Websites in der Regel alle relevanten Seiten crawlt. Besonders kritisch wird es bei sehr großen Websites mit 100.000 oder mehr URLs und bei Projekten mit sehr häufigen Content-Updates, wo eine aktive Priorisierung der wichtigsten Inhalte notwendig wird.
-
Welche AI-Crawler tauchen im Access Log auf?
Im Access Log tauchen unter anderem GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity AI), Google-Extended (Googles AI-Training), Amazonbot, Meta-ExternalAgent und Bytespider (ByteDance) auf. Diese AI-Crawler werden weder von GA4 noch von der Google Search Console erfasst. Das Access Log ist die einzige verlässliche Quelle, um zu sehen, welche AI-Systeme eine Website tatsächlich besuchen und welche URLs sie crawlen.
-
Wann hat Google die Mobile-First-Indexierung vollständig abgeschlossen?
Am 5. Juli 2024 hat Google den letzten Schritt der Mobile-First-Migration umgesetzt: Auch die wenigen bis dahin verbliebenen Websites, die noch mit dem Googlebot Desktop für die Websuche verarbeitet wurden, werden seitdem mit dem Googlebot Smartphone gecrawlt. Google dokumentiert weiterhin beide Crawler-Typen und beschreibt, dass ein kleiner Teil der Requests weiterhin Desktop-basiert sein kann. Für Indexierung und Ranking ist der mobile Crawler damit der primäre Crawler für alle Websites. Im Access Log bedeutet das: Das Verhältnis Googlebot Smartphone zu Googlebot Desktop ist kein zuverlässiger Diagnosewert mehr für den Mobile-First-Status.
-
Warum eignet sich ChatGPT oder ein anderes LLM nicht als primäres Tool für die Logfile-Analyse?
LLMs können Access Logs einlesen und erste Auswertungen liefern, aber sie erkennen nicht alle Bot-User-Agents zuverlässig und interpretieren User-Agent-Strings manchmal fehlerhaft. Für eine fundierte SEO-Analyse sind spezialisierte Tools besser geeignet, die auf die Struktur von Access Logs und die Bedürfnisse von Suchmaschinenoptimierern ausgerichtet sind. LLMs können als ergänzendes Werkzeug für Ad-hoc-Auswertungen dienen, ersetzen aber keine strukturierte Logfile-Analyse.
Könnte dich auch interessieren
-
Crawl-Budget im SEO: Wie Googlebot entscheidet, was er crawlt und was du daran ändern kannst
- Geschrieben von Carsten Feller
- Veröffentlicht am
-
Wenn Suchsysteme raten müssen: Entitätsaufbau als strategische Grundlage für SEO und AI Search
- Geschrieben von Carsten Feller
- Veröffentlicht am
-
SEO nach dem Umbruch: Was 2025 wirklich verändert hat und wer die Rechnung zahlt
- Geschrieben von Carsten Feller
- Veröffentlicht am
-
Duplicate Content: Definition, SEO-Auswirkungen & Lösungen
- Geschrieben von Carsten Feller
- Veröffentlicht am
-
Warum Seiten nicht indexiert werden: GSC-Seitenreport richtig lesen und handeln
- Geschrieben von Carsten Feller
- Veröffentlicht am




